I read the paper Pioneer Agent and found several interesting ideas that are highly relevant for building agentic workflows in production systems. We have used some learning in our production agent monitoring.
One section that stood out was the production mode architecture, which focuses on automated monitoring, failure diagnosis, retraining, and regression prevention for small language models (SLMs).
This blog, I will discuss only the production mode workflow used for monitoring deployed agentic systems, identifying shortcomings, detecting errors, and continuously improving model performance without degrading existing capabilities.
Why Small Language Models Need Production Monitoring
Small language models are attractive for production systems because they consume fewer computational resources and are cheaper to deploy. However, they are often not specialized for domain-specific tasks and face challenges around:
- Data curation
- Failure diagnosis
- Regression avoidance
- Iteration control
The Pioneer Agent framework addresses these challenges through a closed-loop production adaptation system.
Pioneer Agent Production Mode
In production mode, the system starts with:
- A deployed model
-
Judged inference failures from either:
- LLM-as-judge systems
- Human review
The agent then performs the following loop:
- Query production traces
- Construct a failure taxonomy
- Confirm weaknesses through targeted probing
- Generate a corrective training curriculum
- Retrain the model
- Evaluate against failure and regression sets
- Repeat until failures are resolved without degrading previous behavior
The overall objective is not just improving accuracy, but ensuring improvements happen without introducing regressions.
Model Architecture Choices
Another interesting part of the architecture is the separation between encoder and decoder workloads.
Encoder Models
For tasks requiring only encoder architectures, such as:
- Named Entity Recognition (NER)
- Text classification
the system uses GLiNER2.
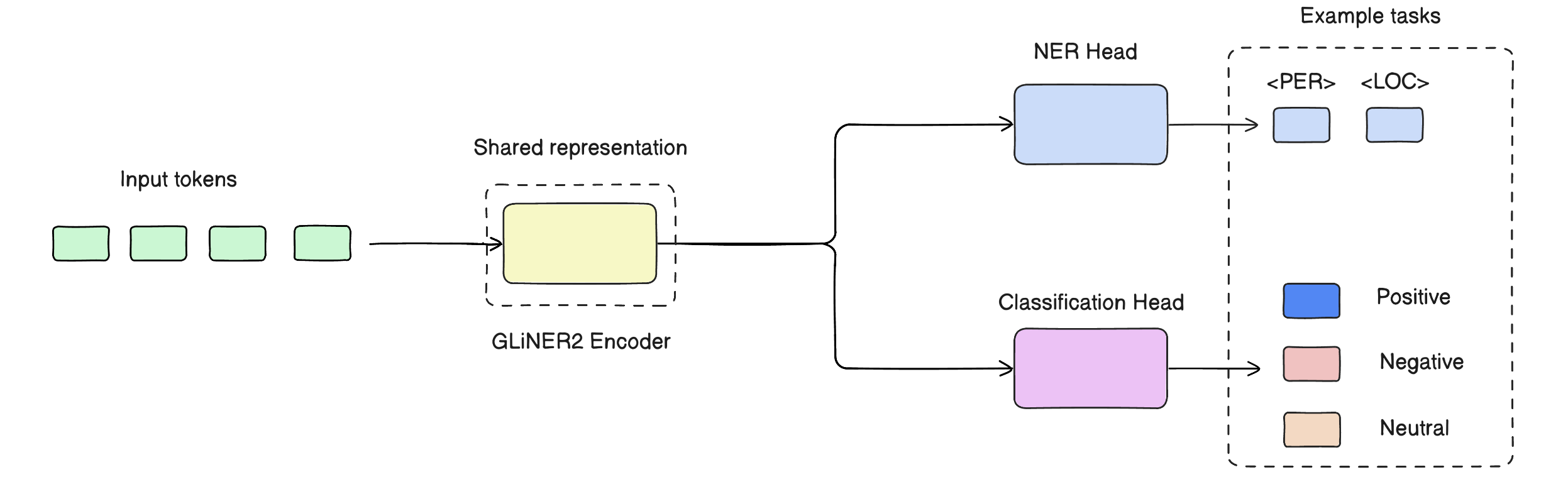
GLiNER2 uses shared representations together with task-specific output layers.
Encoder training supports:
- Full fine-tuning
- LoRA fine-tuning
Since the encoder architecture is relatively small, full parameter updates are still practical.
Decoder Models
For text generation tasks, decoder-only models such as:
- Qwen3-8B
- Llama-3.2-3B
are used.
The Qwen3-8B setup uses the instruction-tuned variant because smaller models benefit significantly from instruction fine-tuning.
The Llama-3.2-3B experiments instead use the non-instruction-tuned variant.
Decoder training is performed using the Tinker SDK, which provides:
- LoRA fine-tuning
- Instant inference on adapted models
Handling Long Context Lengths
The system uses a hierarchical agent architecture to manage long contexts and parallel execution.
The main agent orchestrates the full pipeline for:
- Up to 500 LangGraph turns in production mode
- Up to 1,500 LangGraph turns in cold-start mode
Each turn represents:
- One LLM reasoning step
- Associated tool calls
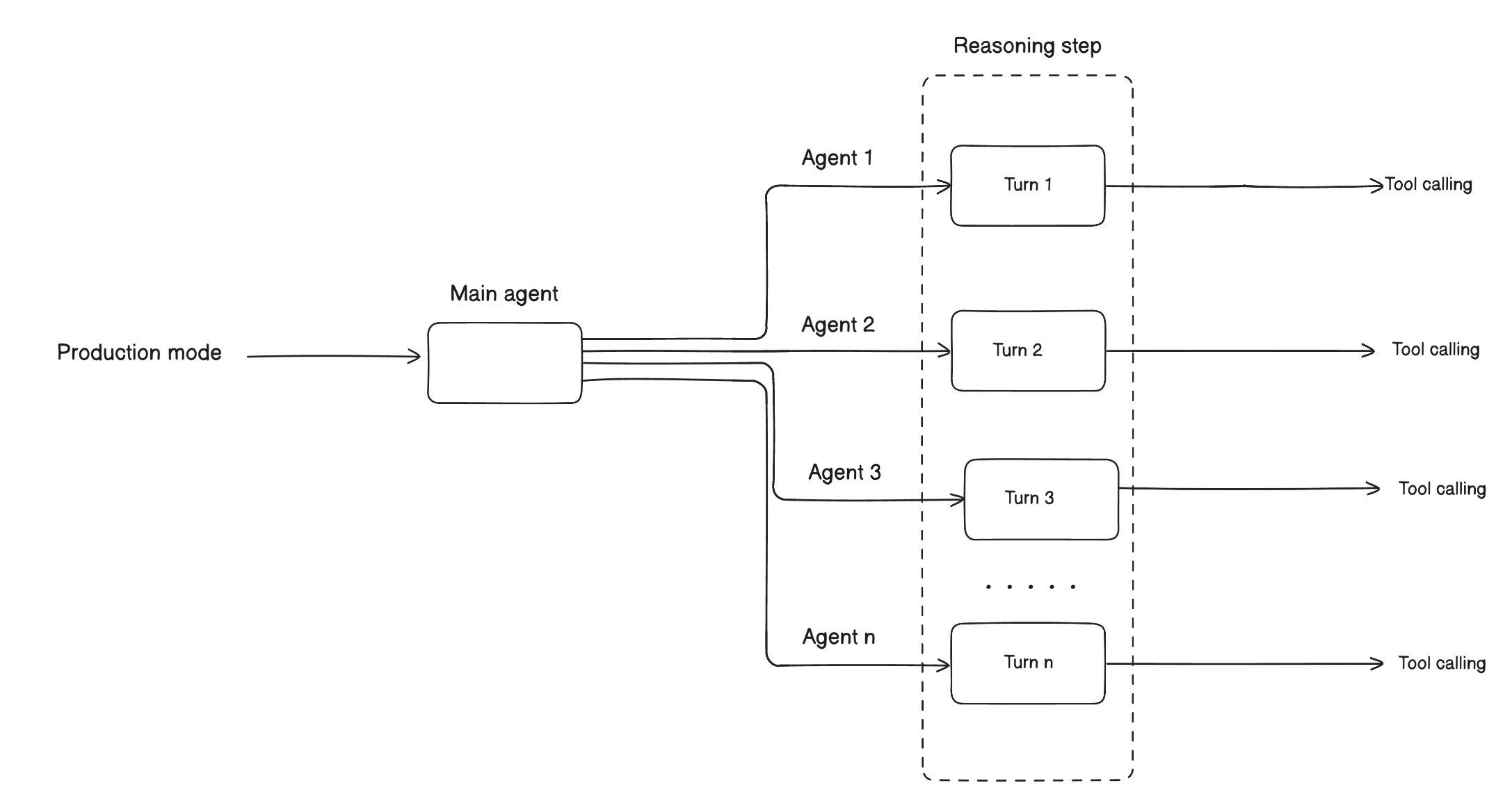
Hierarchical Agent Orchestration
Trace Analyzer Sub-Agent
A specialized Trace Analyzer sub-agent handles:
- Data-heavy SQL analysis
- Long execution traces
with an output-token limit of approximately 100K tokens. There is a limit to keep the token usage in check.
Parallel Sub-Agents
Independent sub-agents can be spawned through parallel execution.
Examples include:
- Building the next dataset while training runs
- Parallel trace analysis
- Concurrent evaluation workflows
Context Manager
A proprietary Context Manager module monitors conversation state and preserves long-term reasoning continuity.
When the conversation approaches the context limit, the system selectively compacts older turns while preserving:
- Key decisions
- Evaluation results
- Dataset lineage
This allows the agent to sustain hundreds of reasoning turns without losing critical state information.
Failure Diagnosis
Failure diagnosis involves identifying the root cause of model errors by analyzing:
- Synthetic inference logs
- Execution traces
- Agent decision traces
The goal is to understand why the model failed and determine whether the issue is fixable through training.
Typical failures include:
- Calculation mistakes
- Reasoning hallucinations
- Missing constraints
- Incorrect assumptions
For example, an agent may conclude that a premium membership costs 100 Euros when the correct value is 500 Euros because the model failed to calculate the required user count.
The decision traces taken by the agent can then be analyzed to diagnose how the incorrect reasoning path was formed.
Production Mode Workflow
The production workflow consists of three major stages:
1. Deployed Model + Judged Traces
The system continuously collects inference traces from the deployed model together with failure judgments from either automated evaluators or humans.

These traces contain:
- Inputs
- Outputs
- Intermediate reasoning
- Tool calls
- Execution history
This creates the foundation for monitoring and diagnosis.
2. Analyze Traces and Cluster Failures
The agent analyzes traces and groups failures into categories.
This taxonomy construction stage helps identify systematic weaknesses instead of isolated errors.
Failures are labeled as:
- Fixable through training
- External or non-trainable issues
The system also performs live confirmation by probing the deployed model with targeted examples to verify whether the weakness is systematic.
Another important component is parent model awareness, where the system inspects the lineage of the deployed model to determine whether corrective training should extend an existing dataset or start from scratch.
3. Synthesize Corrective Curriculum
Once weaknesses are identified, the system generates a corrective training curriculum.
Every training dataset is assembled from three slices.
Gold Examples (40–60%)
These are correct input-output pairs sourced from:
- Downloaded benchmarks in cold-start mode
- Corrected failures in production mode
Hard Negatives (25–35%)
These are confusable examples where the correct answer differs from a plausible alternative.
The objective is to force the model to learn fine-grained decision boundaries.
Replay Buffer (10–20%)
Replay data is sampled from the parent model’s previous training data to prevent catastrophic forgetting.
This component is used only in production mode when improving an already fine-tuned model.
Regression Avoidance
One of the most important concepts in the paper is regression avoidance.
When a model is fine-tuned on a new task, its performance on previous tasks should not degrade. If the model forgets previous capabilities after learning new ones, this is called catastrophic forgetting.
Regression avoidance ensures that:
- Existing capabilities remain stable
- Accuracy on older tasks does not decrease
- New improvements do not silently break previous behavior
For example, after fine-tuning a model on a new workflow task, the model should still maintain its previous accuracy on older production tasks.
Cross-Checkpoint Regression Gate
A major risk in production systems is temporal overfitting.
As new failures are discovered, the evaluation dataset evolves over time. A model may improve on the newest failure slice while degrading on previously solved behaviors.
To prevent this, Pioneer Agent introduces a cross-checkpoint regression gate.
Once a candidate model reaches the score threshold on the current evaluation set, it is also evaluated against the evaluation set from the previous checkpoint.
The model must satisfy the regression constraint on both datasets before deployment.
Combined with the replay buffer, this creates a ratchet effect:
- Previously validated behavior is preserved
- New improvements are incorporated incrementally
- Performance becomes monotonically non-decreasing across iterations
Iteration Control
Iteration control manages the cyclic process of training and evaluation.
The system decides:
- When to continue training
- When to stop
- When to roll back
- When performance degradation has occurred
One obvious trigger for retraining is performance deterioration.
The system follows a structured iteration policy based on validation-set score.
Score < 0.80
The dataset requires fundamental rework.
The agent analyzes remaining failures and identifies issues such as:
- Missing label coverage
- Distribution mismatch
- Insufficient hard negatives
The problem is treated as a data problem rather than a hyperparameter problem.
Score 0.80–0.95
The system focuses on hyperparameter tuning:
- More epochs
- Different learning rates
- Larger base models
- Adjusted LoRA rank
The dataset remains fixed to isolate optimization effects.
Score > 0.95
At this stage, only targeted improvements are added.
The agent inserts 2–3 examples for each remaining failure pattern.
Large-scale data changes are avoided because they increase regression risk.
Regression Detected
If performance decreases compared to the previous iteration, the system immediately rolls back to the previous dataset and configuration.
The framework assumes that more data is not always better.
Structural Safeguards Against Overfitting
Production inference data is often:
- Noisy
- Biased
- Temporally correlated
Several mechanisms help reduce overfitting risk:
- Hard negatives
- Label balancing
- Rollback-first iteration
- Parallel training of multiple configurations
- Regression gating
- Replay buffers
These safeguards constrain both:
- Data composition
- Update acceptance
This ensures that only stable improvements are deployed.
Confidence Calibration
In production systems, model confidence is often poorly aligned with actual correctness, especially under distribution shift.
Models tend to become overconfident on systematic failure modes.
To address this, the system tracks historical accuracy per label and recalibrates confidence scores:
- Correct historical performance increases trust
- Historically incorrect predictions reduce confidence
This improves human-in-the-loop review because high-confidence errors become easier to detect.
The system also uses TF-IDF similarity to identify related unlabeled examples. When a human corrects one prediction, similar examples can also be updated, preventing the same failure pattern from recurring repeatedly.
Final Thoughts
The most interesting aspect of Pioneer Agent is not simply automated fine-tuning, but the production monitoring loop built around failure diagnosis, regression prevention, and controlled iteration.
The framework treats model adaptation as an operational system rather than a one-time training process.
The production mode architecture demonstrates how agentic systems can continuously:
- Monitor failures
- Diagnose root causes
- Generate corrective datasets
- Prevent regressions
- Maintain stable long-term performance
This type of closed-loop adaptation is likely to become a foundational pattern for future production agentic systems using small language models.