I wanted to see if a Gemini LLM, called once per epoch, could pick a better learning rate than a fixed StepLR schedule for ResNet-18 on CIFAR-10.
I ran six variants. Each one sent Gemini a different piece of training context — recent losses, the LR history, gradient norms, or per-class accuracy — and let it set the next epoch’s learning rate. None of them beat the baseline. But the way each one failed was different, and the per-class-accuracy run was the only one where the LLM ever raised the LR instead of cutting it.
The setup, results, and what I learned are below.
The setup
ResNet-18 on full CIFAR-10, 20 epochs, SGD with momentum 0.9 and weight decay 1e-3. Starting LR is 0.1. The baseline is StepLR(step_size=5, gamma=0.1) — every 5 epochs the LR drops 10×.
For the LLM runs, I use Gemini 2.5 Flash. After each epoch I send a short prompt with the current LR plus some training signal, then parse a number out of the reply. If it’s between 0 and 1, the optimizer uses it. Otherwise the scheduler’s value stays.
Same seed in every run, so the first epoch is identical across all of them.
How the LR was chosen each epoch
Every variant runs the same loop. After each epoch:
- StepLR steps first. It cuts the LR by 10× at epochs 5, 10, 15, 20, and does nothing on the others.
- Then Gemini gets a chance to overwrite it. I send a prompt, then a regex pulls the first number after the phrase “learning rate” or “LR” out of the reply. If it’s between 0 and 1, it overwrites the LR for the next epoch. Otherwise the scheduler’s value is kept.
The arms only differ in what extra signal Gemini sees in the prompt:
| Arm | What was sent to Gemini | How the next epoch’s LR was decided |
|---|---|---|
StepLR only |
(Gemini not called) | StepLR’s 10× decay every 5 epochs |
| every 3 / 5 epochs | recent losses + current LR | StepLR — Gemini was called but never produced a number that passed the parse + range check |
| every epoch, losses only | recent losses + current LR | First number Gemini named after “LR” — in practice always lower than current |
| + LR history | losses + the full per-epoch LR history | same parse rule, more context in the prompt |
| + gradient norms | losses + per-epoch average L2 gradient norm + trend label | same |
| + per-class accuracy | losses + per-class test accuracy + the worst three classes | same |
So the different LR trajectories you see across arms come from the same selection rule reacting to different prompt content — not a different algorithm.
What a single call looks like
Here’s the actual exchange from epoch 1 of the LR-history run:
Prompt sent to Gemini:
Based on the following training loss trajectory, what would be a recommended new learning rate?
- Current Learning Rate: 0.1
- Learning rate history (per-epoch, last 1 epochs): [0.1]
- Loss values (last 1 epochs): [2.1745018385865196]
- Overall trend of losses: unchanged or fluctuating
- Recent trend (last 1 epochs): stable
Consider if the learning rate should be increased, decreased, or kept the same, and suggest
a specific value or a strategy (e.g., "reduce by factor of 10"). Also, explain your reasoning
briefly.
Gemini’s response:
A recommended new learning rate would be **0.01**.
**Reasoning:**
The overall trend of "unchanged or fluctuating" losses, combined with the current learning
rate of 0.1, strongly suggests that the learning rate is too high. When the learning rate is
too high, the optimizer tends to overshoot the minimum, causing the loss to bounce around
(fluctuate) or fail to consistently decrease. Reducing the learning rate by a factor of 10
(from 0.1 to 0.01) allows for smaller steps, which can help the optimizer stabilize and
converge more effectively towards a minimum.
The regex pulls 0.01 out of “would be 0.01”, the range check passes, and that becomes epoch 2’s LR. From the log:
[ (scheduler + Gemini) + LR history] Updated LR to 0.01 from LLM suggestion.
The reasoning is “fluctuating loss + high LR → must be too high → cut by 10×.” This is the same instinct the LLM keeps repeating in the other runs, even when the loss is going down nicely.
Results
| Run | Final test acc | Δ vs baseline |
|---|---|---|
StepLR only (baseline) |
88.57% | — |
(scheduler + Gemini) every 3 / 5 epochs (losses only) |
88.57% | ≡ baseline |
(scheduler + Gemini) every epoch, losses only |
71.90% | −16.67 |
(scheduler + Gemini) + LR history |
72.56% | −16.01 |
(scheduler + Gemini) + gradient norms |
66.66% | −21.91 |
(scheduler + Gemini) + per-class accuracy |
79.95% | −8.62 |
First surprise: the every-3 and every-5-epoch runs gave the exact same result as plain StepLR. Gemini was called 6 and 4 times, and every reply either failed to parse or was outside the 0–1 range. Calling the LLM less often didn’t help — it just made it have no effect at all.
When I called it every epoch, things got worse.
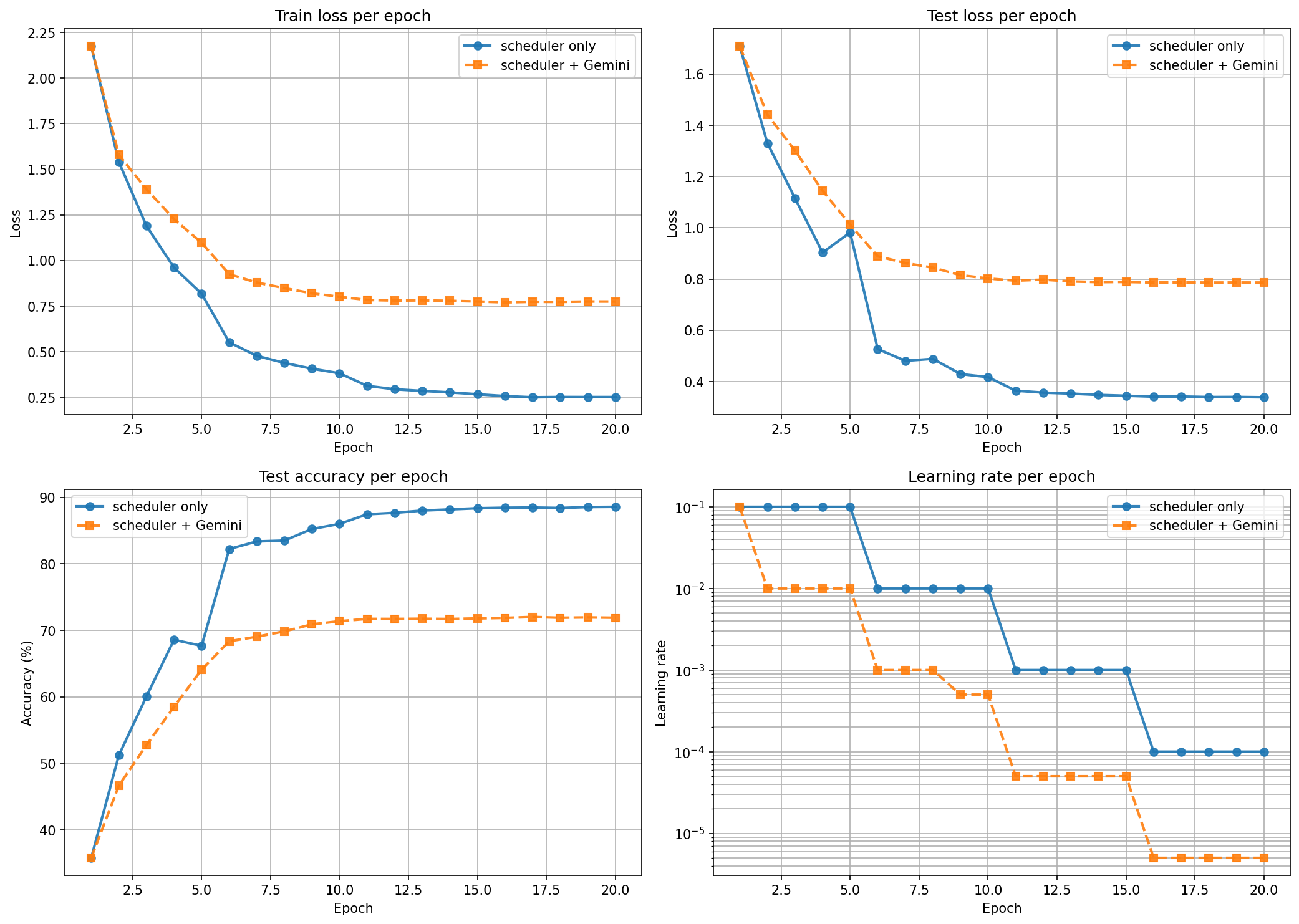
The Gemini run (orange) drops the LR almost immediately and never recovers. Every time the loss flattens a bit, it cuts the LR. By epoch 11 the LR is 5e-6 and training has stalled. Final accuracy: 71.9% vs 88.6% from the baseline.
Idea 1: LR history
Maybe the LLM didn’t have enough context. So I added the full LR history to the prompt.
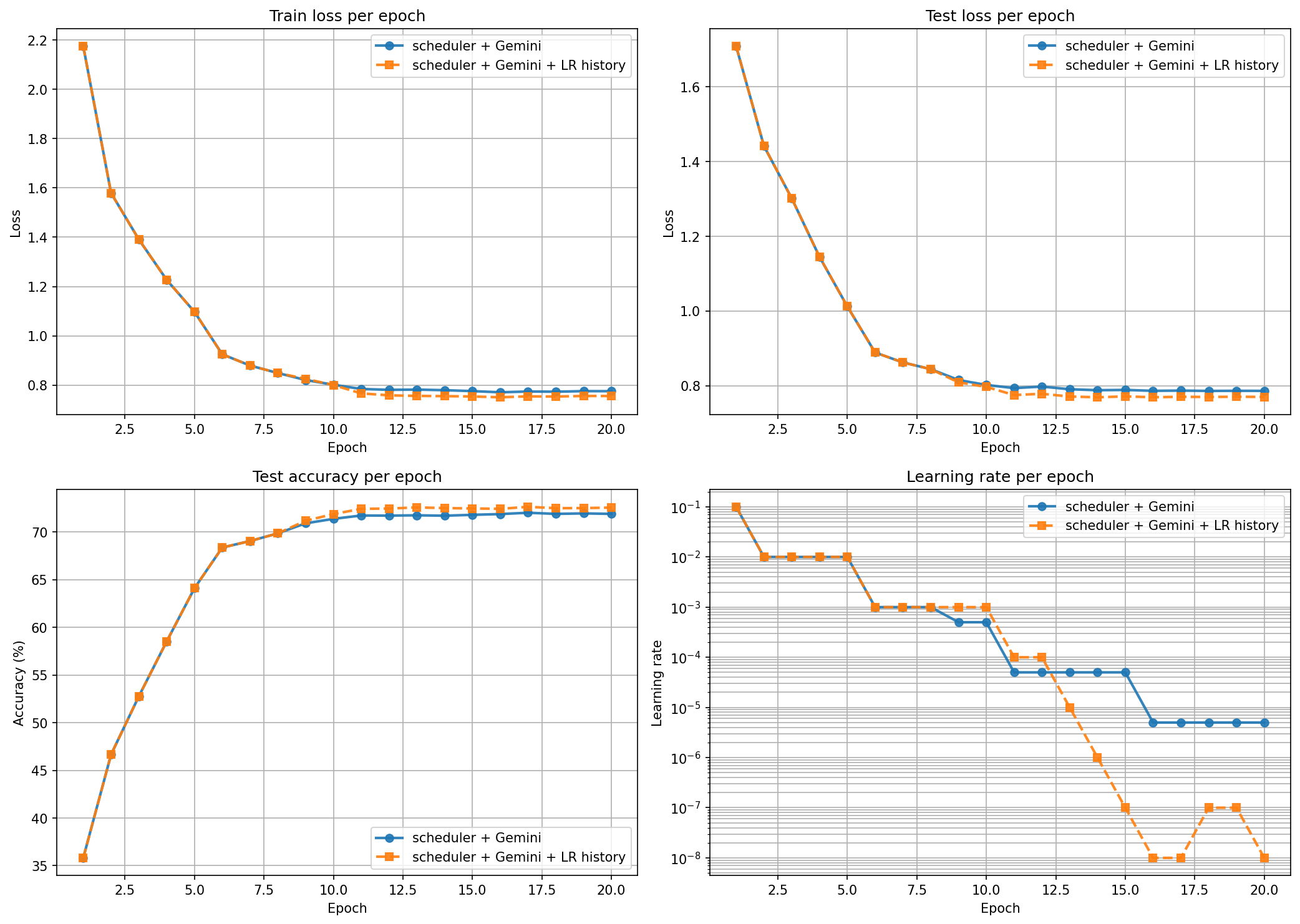
A bit better (72.56% vs 71.90%) but the LR drops harder. With more history to look at, the LLM was more confident in the same wrong answer. The LR ends up at 1e-8 by epoch 16.
Idea 2: gradient norms
I expected this one to work. Gradient norms tell you something the loss curve doesn’t — whether the optimizer is in a sharp or flat region. So I sent the per-epoch average L2 norm and a trend label.
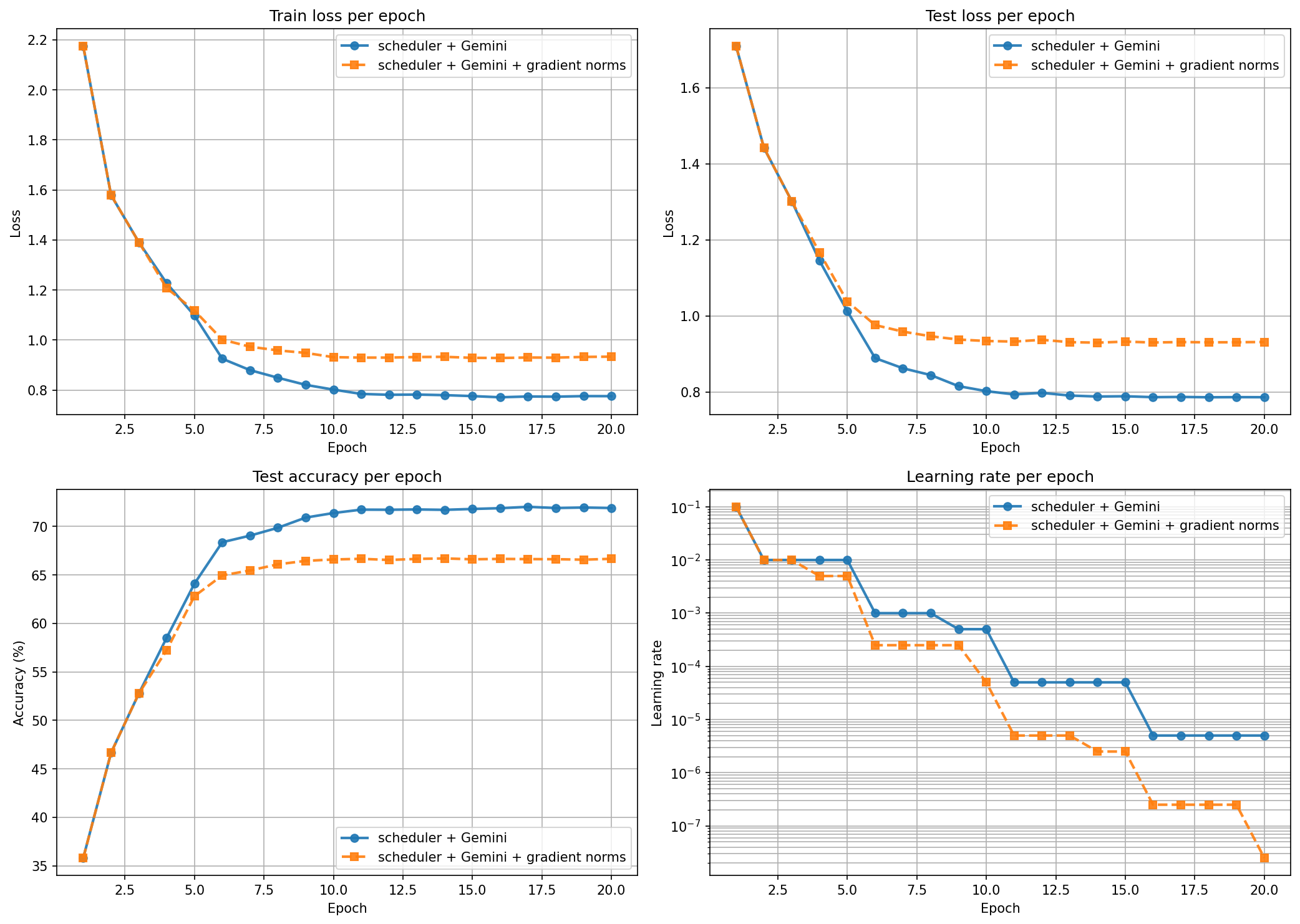
This was the worst run. 66.66%.
The gradient norms went up during training — from ~1.0 in epoch 1 to ~3.5 by epoch 10. That’s normal as the network specializes. But Gemini read rising gradient norms as instability and cut the LR hard. The LR ended at 2.5e-8 and training froze. The signal was fine — the LLM’s response to it wasn’t.
Idea 3: per-class accuracy
Different angle. Instead of telling the LLM about the optimizer, tell it about the model. Each call now included the test accuracy per class — plane: 51.8%, cat: 7.5%, ship: 78.4%, ... — plus the worst three classes.
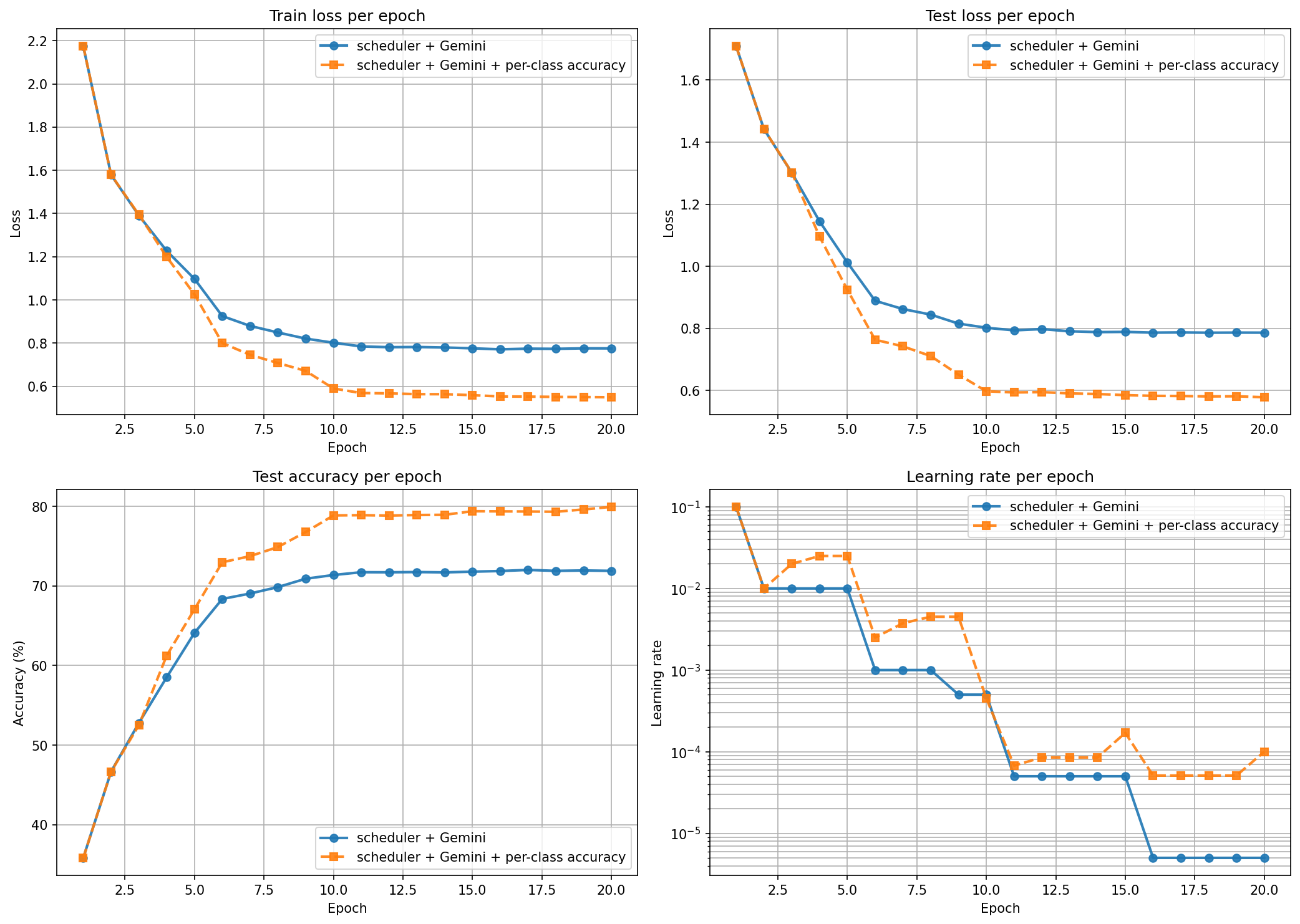
This was the only run where the LLM raised the LR. Around epochs 3–8 it pushed from 0.01 up to 0.025, then 0.0045, instead of cutting. When it saw “cat is at 7.5% and others are 40–70%”, it read the situation as “still room to learn” instead of “stuck.” Final accuracy: 79.95% — still below baseline, but the only LLM run that recovered most of the gap.
What I learned
The result depends a lot on which signal you put in the prompt. Show the LLM loss curves and it cuts the LR. Show it gradient norms and it cuts the LR more. Show it per-class accuracy and it sometimes raises the LR. Same model, same training run — different signals, different behavior.
Loss curves are a bad signal to send. They look exactly like the setup for “lower the LR” advice in any textbook, so the LLM gives that advice even when the loss is going down fine.
Code layout
# experiment runners — one per arm
experiment.py baseline (StepLR) + (scheduler + Gemini) (losses only)
experiment_cadence.py (scheduler + Gemini) every 3 and 5 epochs
experiment_lr_history.py (scheduler + Gemini) with LR history added
experiment_gradient_norms.py (scheduler + Gemini) with gradient norms added
experiment_per_class.py (scheduler + Gemini) with per-class accuracy added
# overlay plots — each compares one arm against its baseline
compare_cadence.py cadence runs vs. every-epoch baseline
compare_lr_history.py LR-history run vs. losses-only baseline
compare_gradient_norms.py gradient-norm run vs. losses-only baseline
compare_per_class.py per-class run vs. losses-only baseline
# library code
llm/advisor.py prompt building + Gemini call + LR parsing
training/trainer.py training loop, metric collection
models/classifier.py ResNet-18 + classification head
datasets/cifar10.py CIFAR-10 loaders
viz/plots.py 4-panel comparison plot
# config + outputs
config.py hyperparameters, model name, API key env
artifacts/ saved results.json + comparison.png per run
Running it yourself
pip install -r requirements.txt
export GOOGLE_API_KEY=<your-key> # for any *_advisor* run
python experiment.py # writes artifacts/results.json + comparison.png
python experiment_lr_history.py # writes artifacts/lr_history/...
python compare_lr_history.py # writes the overlay against the baseline
# ... and so on for the other arms
Set SUBSET_RATIO in config.py below 1.0 to iterate faster. NUM_EPOCHS is 20.
Heads up: the every-epoch runs make about 20 Gemini calls per training run, and the free tier runs out. Use the paid tier or Vertex AI to reproduce these.