Karthik Tech Blogs
Summary - Super Resolution
Fast and Accurate Image Super Resolution by Deep CNN with Skip Connection and Network in Network
Current trend
We propose a highly efficient and faster Single Image Super-Resolution (SISR) model with Deep Convolutional neural networks (Deep CNN). Deep CNN have recently shown that they have a significant reconstruction performance on single-image super-resolution. The current trend is using deeper CNN layers to improve performance.The current trend is using deeper CNN layers to improve performance. However, deep models demand larger computation resources and are not suitable for network edge devices like mobile, tablet and IoT devices
Proposed Paper trend
Our model achieves state-of-the-art reconstruction performance with at least 10 times lower calculation cost by Deep CNN with Residual Net, Skip Connection and Network in Network (DCSCN).
A combination of Deep CNNs and Skip connection layers are used as a feature extractor for image features on both local and global areas.
Parallelized 1x1 CNNs, like the one called Network in Network, are also used for image reconstruction. That structure reduces the dimensions of the previous layer’s output for faster computation with less information loss, and make it possible to process original images directly
Also we optimize the number of layers and filters of each CNN to significantly reduce the calculation cost. Thus, the proposed algorithm not only achievesstateof-the-art performance but also achieves faster and more efficient computation.
Recent Advancement
Recent Deep-Learning based methods (especially with deeply and fully convolutional networks) have achieved high performance in the problem of SISR from low resolution (LR) images to high resolution (HR) images. We believe this is because deep learning can progressively grasp both local and global structures on the image at same time by cascading CNNs and nonlinear layers. However, with regards to power consumption and real-time processing, deeply and fully convolutional networks require large computation and a lengthy processing time.
Paper Advancement
In this paper, we propose a lighter network by optimizing the network structure with recent deep-learning techniques, as shown in Figure 1. For example, recent state-of-the-art deep-learning based SISR models which we will introduce at section 2 have 20 to 30 CNN layers, while our proposed model (DCSCN) needs only 11 layers and the total computations of CNN filters are 10 to 100 times smaller than the others.
Related Work:
- SRCNN - Super-Resolution Convolutional Neural Network. use 2 to 4 CNN layers to prove that the learned CNN layers model performs well on SISR (Single Image Super Resolution) tasks. The authors concluded that using a larger CNN filter size is better than using deeper CNN layers.
- DRCN Deeply-Recursive Convolutional Network for Image SuperResolution.DRCN uses deep (a total of 20) CNN layers, which means the model has huge parameters. However, they share each CNN’s weight to reduce the number of parameters to train, meaning they succeed in training the deep CNN network and achieving significant performances.
- VDSR uses Deep Residual Learning, which was developed by researchers from Microsoft Research and is famous for receiving first place in ILSVRC 2015 (a large image classification competition). By using residual-learning and gradient clipping, VDSR proposed a way of significantly speeding up the training step.
- Very deep Residual Encoder-Decoder Networks (RED) are also based on residual learning. RED contains symmetric convolutional (encoder) and deconvolutional (decoder) layers. It also has skip connections and connects instead to every two or three layers. Using this symmetric structure, they can train very deep (30 of) layers and achieve state-of-the-art performance. These studies therefore reflect the trend of “the Deeper the Better”.
- RAISR Rapid and Accurate Image Super Resolution (RAISR), which is a shallow and faster learning-based method. It classifies input image patches according to the patch’s angle, strength and coherence and then learn maps from LR image to HR image among the clustered patches.
RAISR and FRSCNN’s processing speeds are 10 to 100 times faster than other state-of-the-art Deep Learning based methods. However, their performance is not as high as other deeply convolutional methods, like DRCN, VDSR or RED.
Proposed method
We started building our model from scratch. Started from only 1 CNN layer with small dataset and then grow the number of layers, filters and the data. When it stopped improving performance, we tried to change the model structure and tried lots of deep learning technics like mini-batch, dropout, batch normalization, regularizations, initializations, optimizers and activators to learn the meanings of using each structures and technics. Finally, we carefully chose structures and hyper parameters which will suit for SISR task and build our final model.
Model Overview:

Steps:
- We cascade a set of CNN weights, biases and non-linear layers to the input.
- Then, to extract both the local and the global image features, all outputs of the hidden layers are connected to the reconstruction network as Skip Connection.
- After concatenating all of the features, parallelized CNNs (Network in Network ) are used to reconstruct the image details.
- The last CNN layer outputs the 4ch (or the channels of square of scale factor) image and finally the up-sampled original image is estimated by adding these outputs to the up-sampled image constructed by bicubic interpolation.
- Thus the proposed CNN model focusses on learning the residuals between the bicubic interpolation of the LR image and the HR original image.
In the previous studies, an up-sampled image was often used as their input for the Deep Learning-based architecture. In these models, the SISR networks will be pixelwise. However, 20-30 CNN layers are necessary for each up-sampled pixel and heavy computation (up to 4x, 9x and 16x) is required, as shown in Figure 2. It also seems inefficient to extract a feature from an up-sampled image rather than from the original image, even from the perspective of the reconstruction process.
Feature Extraction Network
- In the first feature extraction network, we cascade 7 sets of 3x3 CNN, bias and Parametric ReLU units. Each output of the units is passed to the next unit and simultaneously skipped to the reconstruction network.
- Unlike with other major deep-learning based large-scale image recognition models, the number of units of CNN layers are decreased from 96 to 32. it is important to use an appropriate number of training parameters to optimize the network. Since the local feature is more important than the global feature in SISR problems, we reduce the features by the following layer and it results in better performance with faster computation.
- We also use the Parametric ReLU units as activation units to handle the “dying ReLU” problem [11]. This prevents weights from learning a large negative bias term and can lead to a slightly better performance.
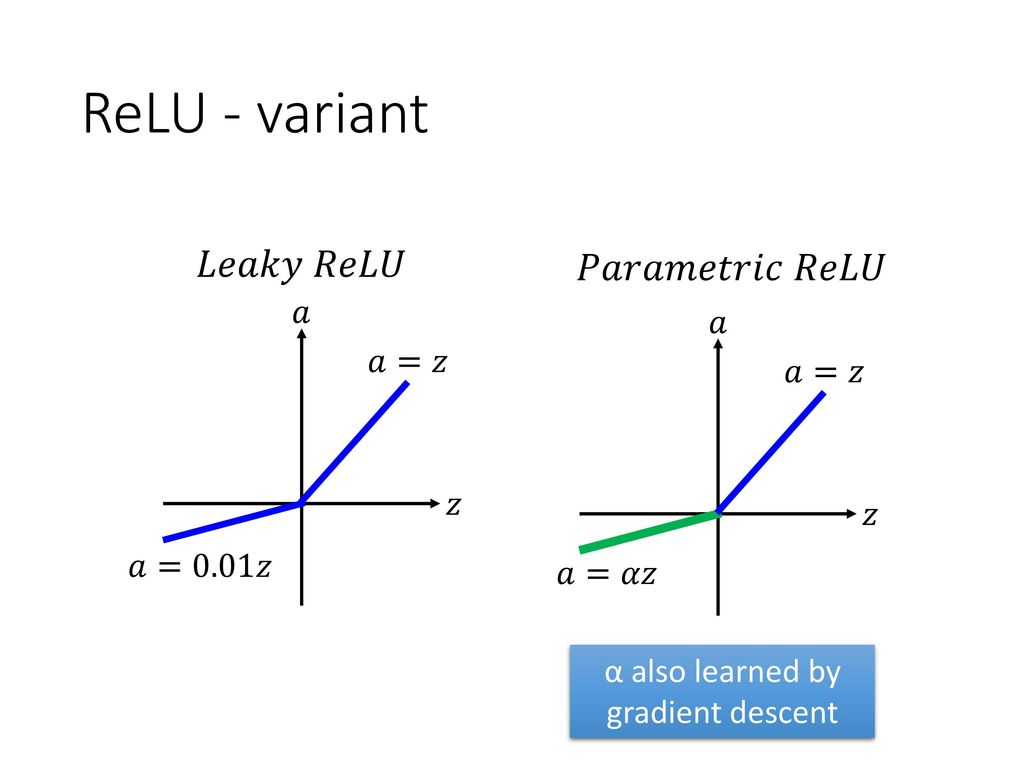
Image reconstruction network
- DCSCN directly processes original images so that it can extract features efficiently.
- The final HR image is reconstructed in the last half of the model and the network structure is like in the Network in Network [2]. Because of all of the features are concatenated at the input layer of the reconstruction network, the dimension of input data is rather large. So we use 1x1 CNNs to reduce the input dimension before generating the HR pixels.
Numerical Explanation:
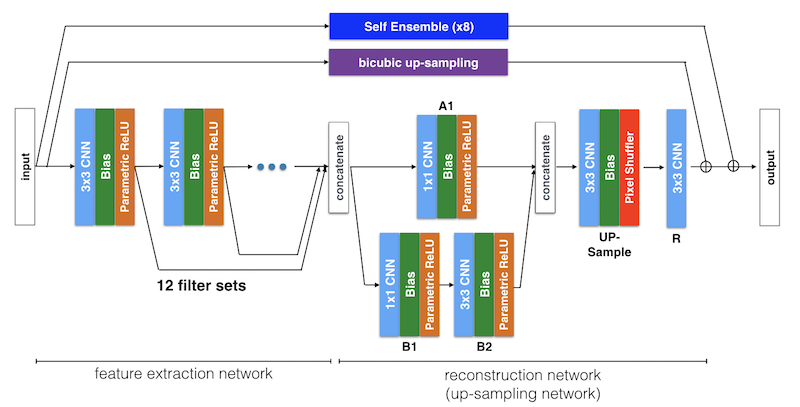
- The last CNN, outputs 4 channels (when the scale factor s = 2).
- Each channel represents each corner-pixel of the up-sampled pixel.
- DCSCN reshapes the 4ch LR image to an HR(4x) image and then finally it is added to the bi-cubic up-sampled original input image.
- As with typical Residual learning networks, the model is made to focus on learning residual output and this greatly helps learning performances, even in cases of shallow (less than 7 layers) models.