Karthik Tech Blogs
Multi-Model Ensemble via Adversarial Learning
This paper presents a method for compressing large, complex trained ensembles into a single network, where knowledge from a variety of trained deep neural networks (DNNs) is distilled and transferred to a single DNN.
The source knowledge networks are called teacher model, and the learning network is called student network.
Adversarial based learning strategy is employed to distill diverse knowledge from different trained teacher models.
The block wise training loss in the student model
- Guide and optimize the predefined student network to recover the knowledge in teacher models
- Promote the discriminator network to distinguish teacher vs student features simultaneously
Outcome
(1) the student network that learns the distilled knowledge with discriminators is optimized better than the original model;
(2) fast inference is realized by a single forward pass, while the performance is even better than traditional ensembles from multi-original models;
(3) the student network can learn the distilled knowledge from a teacher model that has arbitrary structures.
The traditional ensemble, or called true ensemble, has some disadvantages that are often overlooked.
1) Redundancy: The information or knowledge contained in the trained neural networks are always redundant and has overlaps between with each other. Directly combining the predictions often requires extra computational cost but the gain is limited.
2) Ensemble is always large and slow: Ensemble requires more computing operations than an individual network, which makes it unusable for applications with limited memory, storage space, or computational power such as desktop, mobile and even embedded devices, and for applications in which real-time predictions are needed.
In this paper, the teacher model is a combination of diverse models, then the student model learns a distilled version knowledge from the teacher model.
The student model is trained with soft labels that provide more coverage for co-occurring and visually related objects and scenes rather than traditional one-hot vector labels.
We argue that labels should be informative for the specific image. In other words, the labels should not be identical for all the given images with the same class.
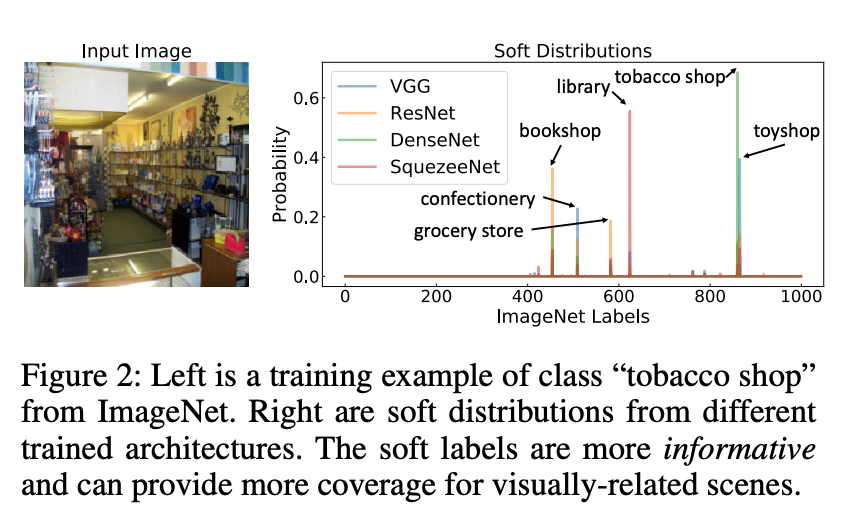
An image of “tobacco shop” has similar appearance to “library” should have a different label distribution than an image of “tobacco shop” but is more similar to “grocery store”. It can also be observed that soft labels can provide the additional intra- and inter-category relations of datasets.
To further improve the robustness of student networks, we introduce an adversarial learning strategy to force the student to generate similar outputs as teachers.
An end-to-end framework with adversarial learning is designed based on the teacher-student learning paradigm for deep neural network ensembling.
• The proposed method can achieve the goal of ensembling multiple neural networks with no additional testing cost.
• The proposed method improves the state-of-the-art accuracy on CIFAR-10/100, SVHN, ImageNet for a variety of existing network architectures.
“Implicit” Ensembling. Essentially, our method is an “implicit” ensemble which usually has high efficiency during both training and testing. The typical “implicit” ensemble methods include: Dropout (Srivastava et al. 2014), DropConnection (Wan et al. 2013), Stochastic Depth (Huang et al. 2016), Swapout (Singh, Hoiem, and Forsyth 2016), etc.
These methods generally create an exponential number of networks with shared weights during training and then implicitly ensemble them at test time.
The typical way of transferring knowledge is the teacher-student learning paradigm, which uses a softened distribution of the final output of a teacher network to teach information to a student network.
Siamese-like Network Structure
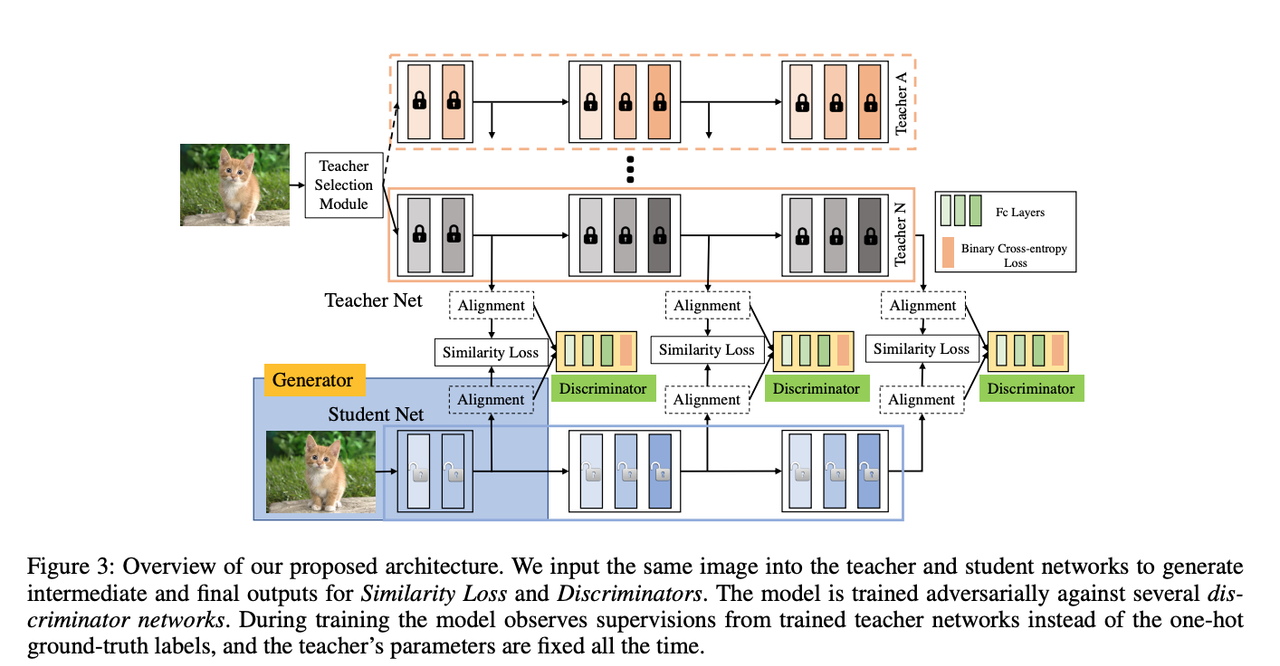
Our framework is a siamese-like architecture that contains two-stream networks in teacher and student branches. The structures of two streams can be identical or different, but should have the same number of blocks, in order to utilize the intermediate outputs. The whole framework of our method is shown in Fig. 3. It consists of a teacher network, a student network, alignment layers, similarity loss layers and discriminators.
The teacher and student networks are processed to generate intermediate outputs for alignment. The alignment layer is an adaptive pooling process that takes the same or different length feature vectors as input and output fixed-length new features. We force the model to output similar features of student and teacher by training student network adversarially against several discriminators. We will elaborate each of these components in the following sections with more details.
Once the teacher network is trained, we freeze its parameters when training the student network.
We train the student network by minimizing the similarity distance between its output and the soft label generated by the teacher network.
We investigated three distance metrics in this work, including L1, L2 and KL-divergence.
Adaptive Pooling
The purpose of the adaptive pooling layer is to align the intermediate output from teacher network and student network. This kind of layer is similar to the ordinary pooling layer like average or max pooling, but can generate a predefined length of output with different input size. Because of this specialty, we can use the different teacher networks and pool the output to the same length of student output. Pooling layer can also achieve spatial invariance when reducing the resolution of feature maps.
Because we adopt multiple intermediate layers, our final similarity loss is a sum of individual one:
We generate student output by training the student network and freezing the teacher parts adversarially against a series of stacked discriminators.
A discriminator D attempts to classify its input x as teacher or student.
Using multi-Stage discriminators can refine the student outputs gradually.
Joint Training of Similarity and Discriminators
We achieve ensemble with a training method that is simple and straight-forward to implement. As different network structures can obtain different distributions of outputs, which can be viewed as soft labels (knowledge), we adopt these soft labels to train our student, in order to compress knowledge of different architectures into a single network. Thus we can obtain the seemingly contradictory goal of ensembling multiple neural networks at no additional testing cost.
Learning Procedure
To clearly understand what the student learned, we define two conditions.
-
First, the student has the same structure as the teacher network.
-
Second, we choose one structure for student and randomly select a structure for teacher in each iteration as our ensemble learning procedure.
The learning procedure contains two stages.
- First, we pretrain the teachers to produce a model zoo. Because we use the classification task to train these models, we can use the softmax cross entropy loss as the main training loss in this stage.
- Second, we minimize the loss function to make the student output similar to that of the teacher output.