Karthik Tech Blogs
EfficientDet
Paper: EfficientDet
This paper discusses about the optimized approach in Image detection tasks and compares it with other detection models such as YOLOv3, MaskRCNN and many more by building a scalable detection architecture.
It proposes a weighted Bi-directional feature pyramid network (BiFPN), which allows easy and fast multi-scale feature fusion. Secondly a compound scaling method that uniformly scales the resolution, depth, and width for all backbone, feature network, and box/class prediction networks at the same time.
There two important challenges this paper solves.
Multi Scale Feature Fusion
When there are different input features are at different resolutions, we observe they usually contribute to the fused output feature unequally. To address this issue, the paper proposes a simple and effective weighted bi-directional feature pyramid network (BiFPN), which introduces learnable weights to learn the importance of different input features, while repeatedly applying top-down and bottom-up multi-scale feature fusion.
Model Scaling
A compound scaling method for object detectors, which jointly scales up the resolution/depth/width for all backbone, feature network, box/class prediction network.
BiFPN
The paper first formulate the multi-scale feature fusion problem. Later, introduce two main ideas for the proposed BiFPN: Efficient bidirectional cross-scale connections and weighted feature fusion.
Multi-scale feature fusion aims to aggregate features at different resolutions. Given a list of multi-scale features and our goal is to find a transformation that can effectively aggregate different features and output a list of new features .
Cross-Scale Connections
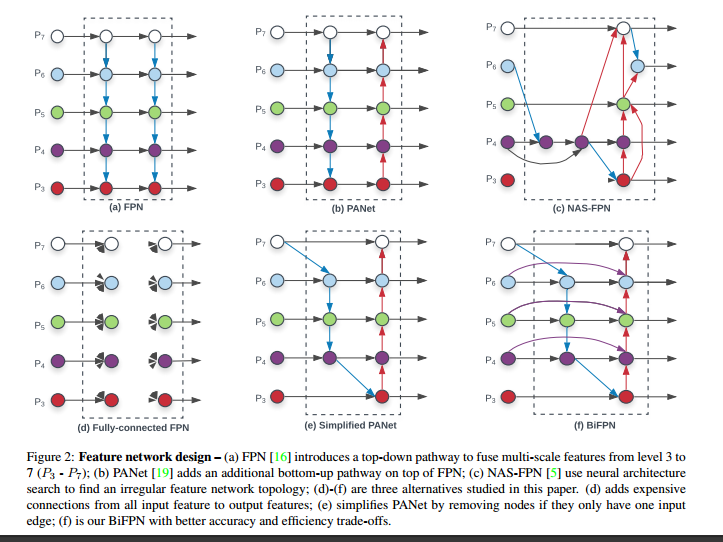
Conventional top-down FPN is inherently limited by the one-way information flow. This paper proposes three improvement for PANet, since it performs at a better accuracy than FPN and NAS-FPN but with the cost of more parameters and computations.
To improve model efficiency, this paper proposes several optimizations for cross-scale connections:
- First, we remove those nodes that only have one input edge. Our intuition is simple: if a node has only one input edge with no feature fusion, then it will have less contribution to feature network that aims at fusing different features. This leads to a simplified PANet. See Fig(e).
- Second, we add an extra edge from the original input to output node if they are at the same level, in order to fuse more features without adding much cost. See Fig(f).
- Third, unlike PANet that only has one top-down and one bottom-up path, we treat each bidirectional (top-down & bottom-up) path as one feature network layer, and repeat the same layer multiple times to enable more high-level feature fusion.
Weighted Feature Fusion
When fusing multiple input features with different resolutions, a common way is to first resize them to the same resolution and then sum them up. Previous feature fusion methods treat all input features equally without distinction. However, we observe that since different input features are at different resolutions, they usually contribute to the output feature unequally. To address this issue, we propose to add an additional weight for each input during feature fusion, and let the network to learn the importance of each input feature.
EfficientDet Architecture
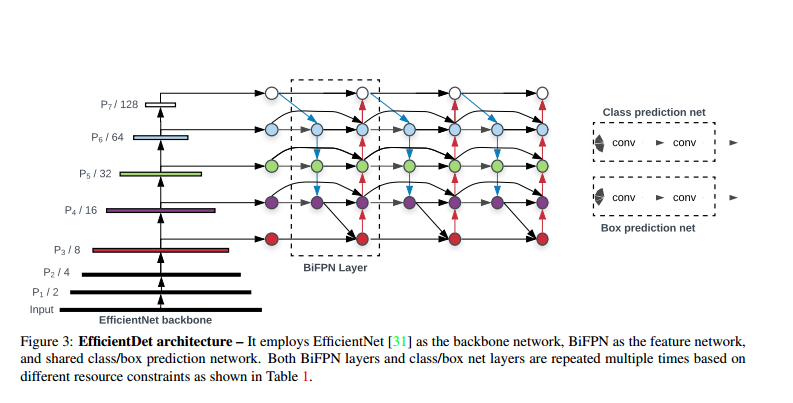
The paper employs ImageNet pretrained EfficientNets as the backbone network. The proposed BiFPN serves as the feature network, which takes level 3-7 features {P3, P4, P5, P6, P7} from the backbone network and repeatedly applies top-down and bottom-up bidirectional feature fusion. These fused features are fed to a class and box network to produce object class and bounding box predictions respectively.
Compound Scaling
The paper proposes a new compound scaling method for object detection, which uses a simple compound coefficient φ to jointly scale up all dimensions of backbone network, BiFPN network, class/box network, and resolution.
Backbone Network
The paper reused the same width/depth scaling coefficients of EfficientNet-B0 to B6, such that they could easily reuse their ImageNet pretrained checkpoints.
BiFPN Network
The paper has exponentially grown BiFPN width (#channels) but linearly increase depth (#layers). Since depth needs to be rounded to small integers.
Box/class prediction network
The width was always the same as BiFPN, but linearly increase the depth (#layers).
Input image resolution
Since feature level 3-7 are used in BiFPN, the input resolution must be dividable by 2^7 = 128, so they linearly increased resolutions.
Models comparision
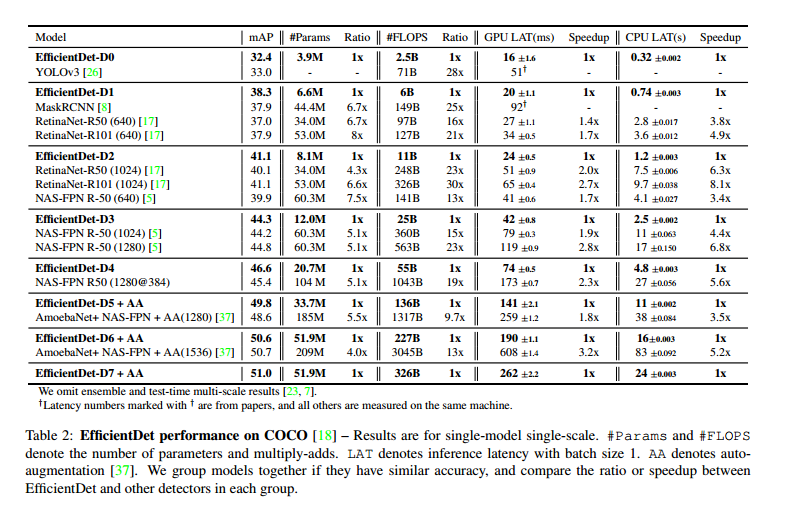
Experiments
-
Each model is trained using SGD optimizer with momentum 0.9 and weight decay 4e-5.
-
Learning rate is first linearly increased from 0 to 0.08 in the initial 5% warm-up training steps and then annealed down using cosine decay rule.
-
Batch normalization is added after every convolution with batch norm decay 0.997 and epsilon 1e-4. We use exponential moving average with decay 0.9998.
-
They employed commonly-used focal loss with α = 0.25 and γ = 1.5, and aspect ratio {1/2, 1, 2}.
-
The models are trained with batch size 128
Written on November 22nd , 2019 by Karthik