Karthik Tech Blogs
Training LLM
Hi everyone, I have written this blog post to share steps and my knowledge on how to fine tune a Large language model at ease.
Introduction
I am using the huggingface library to fine tune the “bigscience/bloom-7b1” model using LoRA (Low rank adaptation of large language models).
bigscience/bloom-7b1 is a BigScience Large Open science open access multilingual language model.
I am fine tuning a LLM with an huggingface dataset, the model can trained with your custom dataset that follows the huggingface dataset format. I am using LoRA method to reduce the re-training the entire model weights but fine tune the lower dimensional matrices obtained from Matrix decomposition with lower rank. This effectively reduces the quantity of parameters that can be fine-tuned for subsequent tasks.
The dataset that I have used here is to generate a prompt based on the roles. For example,
Input: Student
Prompt Output: I want you to act as a student. I will provide some information and you will respond with what you learned about this topic. I want you to only reply with...
Package Installation
-
bitsandbytes is a lightweight wrapper around CUDA custom functions, in particular 8-bit optimizers, matrix multiplication and quantization functions.
- Datasets is a library for easily accessing and sharing datasets for Audio, Computer Vision, and Natural Language Processing (NLP) tasks.
- Accelerate was created for PyTorch users who like to write the training loop of PyTorch models but are reluctant to write and maintain the boilerplate code needed to use multi-GPUs/TPU/fp16.
- loralib - PyTorch implementation of low-rank adaptation (LoRA), a parameter-efficient approach to adapt a large pre-trained deep learning model which obtains performance on-par with full fine-tuning.
- Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient adaptation of pre-trained language models (PLMs) to various downstream applications without fine-tuning all the model’s parameters.
!pip install -q bitsandbytes datasets accelerate loralib
!pip install -q git+https://github.com/huggingface/transformers.git@main git+https://github.com/huggingface/peft.git
Auto Classes
-
AutoClasses can infer the appropriate architecture for your needs based on the name or location of the pretrained model by providing to the
from_pretrained()method. - AutoClasses are designed to simplify this process, allowing to automatically obtain the appropriate model based on the provided name/path for pretrained weights, configuration, or vocabulary.
- AutoTokenizer is a generic tokenizer class that will be instantiated as one of the tokenizer classes of the library.
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0"
import torch
import torch.nn as nn
import bitsandbytes as bnb
from transformers import AutoTokenizer, AutoConfig, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained(
"bigscience/bloom-7b1",
load_in_8bit=True,
device_map='auto',
)
tokenizer = AutoTokenizer.from_pretrained("bigscience/bloom-7b1")
Iterate over the model’s parameters and enable gradients for each layer to allow training, or disable them to freeze the layer.
for param in model.parameters():
param.requires_grad = False # freeze the model - train adapters later
if param.ndim == 1:
# cast the small parameters (e.g. layernorm) to fp32 for stability
param.data = param.data.to(torch.float32)
model.gradient_checkpointing_enable() # reduce number of stored activations
model.enable_input_require_grads()
class CastOutputToFloat(nn.Sequential):
def forward(self, x): return super().forward(x).to(torch.float32)
model.lm_head = CastOutputToFloat(model.lm_head)
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
Fine-tuning large-scale Pretrained Language Models (PLMs) can be very expensive. However, PEFT (Parameter-Efficient Fine-Tuning) methods focus on fine-tuning only a limited number of additional model parameters, significantly reducing computational and storage expenses. Recent cutting-edge PEFT techniques achieve performance that is on par with full fine-tuning.
LoraConfig takes the configuration on the model parameters such as the
-
r - Lora attention dimension
-
target_modules - The names of the modules to apply Lora to
-
lora_alpha - The alpha parameter for Lora scaling
-
lora_dropout - The dropout probability for Lora layers
from peft import LoraConfig, get_peft_model
config = LoraConfig(
r=16, #attention heads
lora_alpha=32, #alpha scaling
# target_modules=["q_proj", "v_proj"], #if you know the
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM" # set this for CLM or Seq2Seq
)
model = get_peft_model(model, config)
print_trainable_parameters(model)
For fine tuning task, I am using the prompt generator task from the huggingface datasets. Given a role, the model is finetuned to generate the prompts.
Dataset: Awesome chatgpt prompts
import transformers
from datasets import load_dataset
data = load_dataset("fka/awesome-chatgpt-prompts")
Create a prediction column by concatenating act and prompt column.
# example["prediction"] = example["act"] + " ->: " + str(example["prompt"])
def merge_columns(example):
example["prediction"] = example["act"] + " ->: " + example["prompt"]
return example
data['train'] = data['train'].map(merge_columns)
data['train']["prediction"][:5]
data = data.map(lambda samples: tokenizer(samples['prediction']), batched=True)
sample data output
data
# output
DatasetDict({
train: Dataset({
features: ['act', 'prompt', 'prediction', 'input_ids', 'attention_mask'],
num_rows: 153
})
})
transformers trainer to fine tune the model.
trainer = transformers.Trainer(
model=model,
train_dataset=data['train'],
args=transformers.TrainingArguments(
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
warmup_steps=100,
max_steps=200,
learning_rate=2e-4,
fp16=True,
logging_steps=1,
output_dir='outputs'
),
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False)
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
Training loss decreases when trained for 200 epochs.
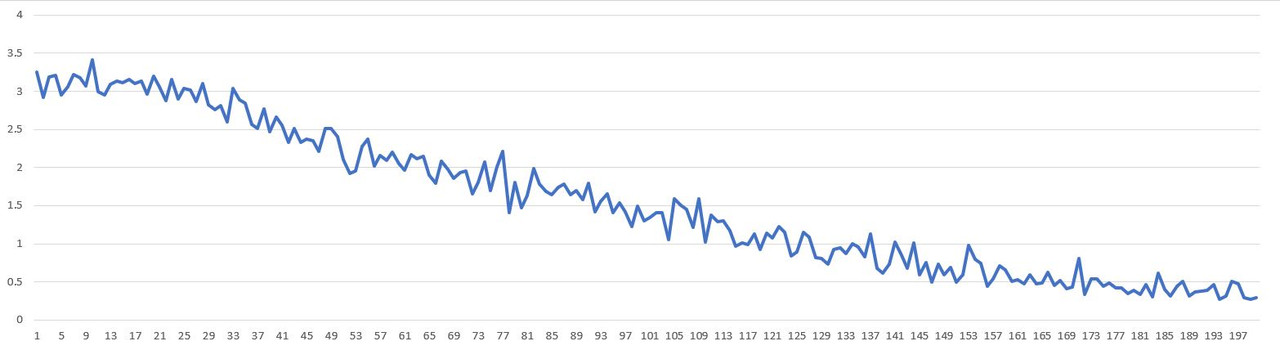
Training Output:
TrainOutput(global_step=200, training_loss=1.54565869897604, metrics={'train_runtime': 3026.3184, 'train_samples_per_second': 1.057, 'train_steps_per_second': 0.066, 'total_flos': 1.5268166706315264e+16, 'train_loss': 1.54565869897604, 'epoch': 20.51})
Inference
Customize the max_new_tokens based on the output sentence length requirement.
batch = tokenizer("“student” ->: ", return_tensors='pt')
with torch.cuda.amp.autocast():
output_tokens = model.generate(**batch, max_new_tokens=500)
print('\n\n', tokenizer.decode(output_tokens[0], skip_special_tokens=True))
Sample Model Prediction
Input:
“student” ->:
Output:
I want you to act as a student. I will provide some information and you will respond with what you learned about this topic. I want you to only reply with what is learned and nothing else. Do not write explanations. My first request is "I am a business student and I am interested in learning about the role of business in the 21st century, and how to apply business principles in order to create a more sustainable environment." My first sentence should not include the word " business" because I have not included that in my information request. My first sentence should be clear and concise and include only the information that I have provided. My first sentence should not include any references or additional information. My first sentence should not be a summary. My first sentence should not include any personal opinions or feelings. My first sentence should not be too long or too short. My first sentence should not include any references. My first sentence should not be formal or informal. My first sentence should not include any typos. My first sentence should not be too specific or too general. My first sentence should not include any examples. My first sentence should not include any statistics. My first sentence should not include any links. My first sentence should not include any cultural references. My first sentence should not include any political references. My first sentence should not include any economic references. My first sentence should not include any technical terms. My first sentence should not include any jargon. My first sentence should not include any abbreviations. My first sentence should not include any personal experiences. My first sentence should not include any family information. My first sentence should not include any personal details. My first sentence should not include any personal opinions. My first sentence should not include any personal feelings. My first sentence should not include any personal details. My first sentence should not include any personal experiences. My first sentence should not include any family information. My first sentence should not include any personal details. My first sentence should not include any personal opinions. My first sentence should not include any personal feelings. My first sentence should not include any personal details. My first sentence should not include any personal experiences. My first sentence should not include any family information. My first sentence should not include any personal opinions. My first sentence should not include any personal feelings. My first sentence should not include any personal details. My first sentence should not include any personal experiences. My first sentence should not include any family information. My first sentence should not include any personal opinions. My first
Model
The fine tuned model is available in huggingface hub at [bloom-7b1-lora-prompter]. The fine tune preformance can be improved by training it for more number of epochs. The fine tuning can be done on google colab. I will be focusing more on Large Language models in the upcoming blog posts. Feel free to reach for any questions regarding the fine tuning task.
Written on October 7th, 2023 by Karthik