Karthik Tech Blogs
Text Summarization Architectures
Text Summarizing is an important NLP Task. It comprises of two categories, abstractive summarization and extractive summarization. However, the real world application of text summarization is challenging due to human readability and quality. I will try to explain different research approaches and architectures employed. This blog post will focus on complete end to end information about text summarization. This blog is a summarized version of the paper
Neural Abstractive Text Summarization with Sequence-to-Sequence Models: A Survey.
Introduction
Neural abstractive text summarization with sequence to sequence models gained a lot of popularity. Many approaches differ based on network architecture, parameter inference and decoding. Along with this there are some version which focus on efficiency and parallelism for training a model.
Extractive summarization considers the words, phrases and sentences in the summaries from the source article. They are relatively simple since they are selecting the sentences from the source article and produce grammatically correct sentences.
Abstractive summaries, extracts the structural representation from source article and then generates summaries using language generation models. They have a strong potential of producing high quality summaries and can also easily incorporate external knowledge.
Seq2seq Models and Pointer Generator Network
- A Neural Attention Model for Sentence Summarization paper first introduced a neural attention seq2seq model with an attention based encoder and a neural network language model decoder for abstractive sentence summarization task.
\[log \ p(y|x; \theta) = \sum_{i=0}^{N-1} log \ p(y_{i+1} | x, y_c; \theta) \\ \\ \\ y \ is \ the \ output \ sequence \ = (y_1, y_2,.....y_n) \\ c \ is \ the \ context \ length \\ \theta = (E, U, V, W) \\ E \ - \ word \ embedding \ matrix \\ U \ V \ W \ - \ weight \ matrices\]Summarization based on text extraction is inherently limited, but generation-style abstractive methods have proven challenging to build. In this work, we propose a fully data-driven approach to abstractive sentence summarization. Our method utilizes a local attention-based model that generates each word of the summary conditioned on the input sentence. While the model is structurally simple, it can easily be trained end-to-end and scales to a large amount of training data. The model shows significant performance gains on the DUC-2004 shared task compared with several strong baselines.
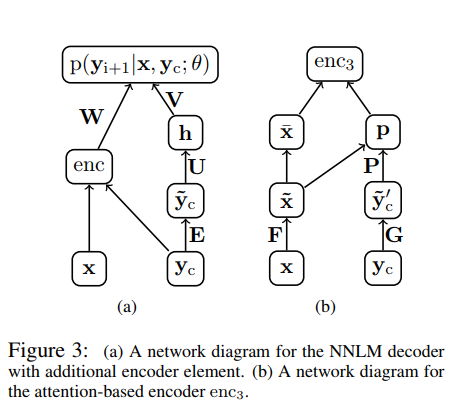
- Abstractive Sentence Summarization with Attentive Recurrent Neural Networks paper extends the above feed forward NNLM with a recurrent neural network. The model is also equipped with a convolutional attention based encoder and a RNN decoder.
Abstractive Sentence Summarization generates a shorter version of a given sentence while attempting to preserve its meaning. We introduce a conditional recurrent neural network (RNN) which generates a summary of an input sentence. The conditioning is provided by a novel convolutional attention-based encoder which ensures that the decoder focuses on the appropriate input words at each step of generation. Our model relies only on learned features and is easy to train in an end-to-end fashion on large data sets. Our experiments show that the model significantly outperforms the recently proposed state-of-the-art method on the Gigaword corpus while performing competitively on the DUC-2004 shared task.
RNN Encoder-Decoder Architecture is used to model the conditional probability. Training involves finding the optimum value for θ, that maximizes the conditional probability of sentence summary pairs in the training corpus.
\[P(y|x; \theta) = \prod_{t=1}^N p(y_t | \{ y_!,....,y_{t-1}\}, x; \theta)\]If the model is trained to generate the next word of the summary, given the previous words, then the above conditional can be factorized into a product of individual conditional probabilities.
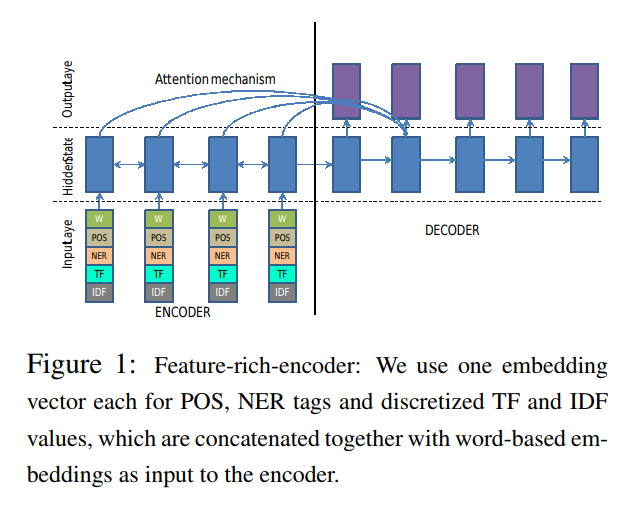
- Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond paper introduced several novel elements to the RNN encoder-decoder architecture to address critical problems in the abstractive text summarization, such as:
-
feature rich encoder to capture keywords.
-
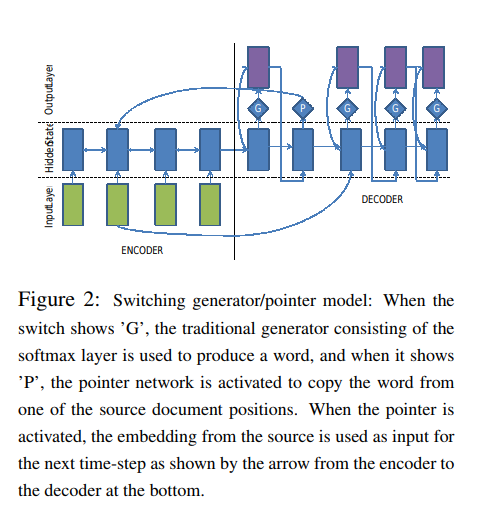
a switching generator pointer to model out-of-vocabulary words.
-
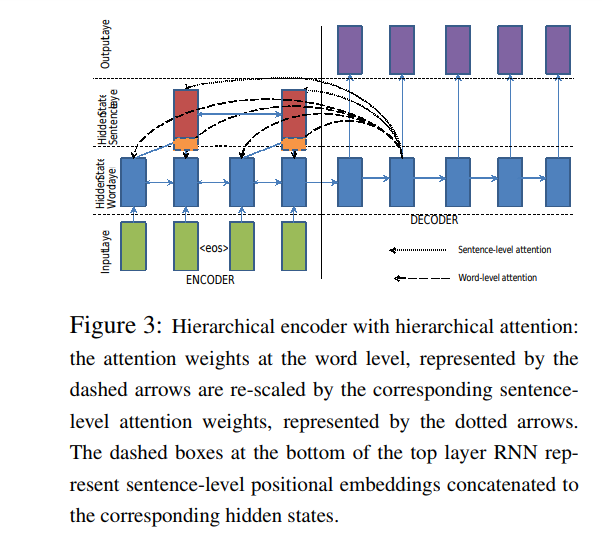
hierarchical attention to capture hierarchical document structures.
In this work, we model abstractive text summarization using Attentional EncoderDecoder Recurrent Neural Networks, and show that they achieve state-of-the-art performance on two different corpora. We propose several novel models that address critical problems in summarization that are not adequately modeled by the basic architecture, such as modeling key-words, capturing the hierarchy of sentence-toword structure, and emitting words that are rare or unseen at training time. Our work shows that many of our proposed models contribute to further improvement in performance. We also propose a new dataset consisting of multi-sentence summaries, and establish performance benchmarks for further research.
-
Handling OOV words
When there is OOV words, the switching decoder/pointer architecture will point to their location in the source document. The decoder is equipped with a ‘switch’ to use the generator or a pointer at every time-step. If the switch is turned on, the decoder produces a word from its target vocabulary. If the switch if turned off, the decoder instead generates a pointer to one of the word-positions in the source. The word at the pointer-location is then copied into the summary. The switch is modeled as a sigmoid activation function.

Learning Hierarchical Document Structure with Hierarchical Attention
Identifying keywords and dominating representation from lenghty source sentences is a challenging task in summarization. The model aims to capture this key sentences using two bi-directional RNNs on the source side, one at the word level and other at the sentence level. The attention mechanism operates at both levels simultaneously.
The word level attention is further re-weighted by the corresponding sentence level attention and re-normalized.
The re-scaled attention is then used to compute the attention weighted context vector that goes as input to the hidden state of the decoder. Further, we also concatenate additional positional embeddings to the hidden state of the sentence-level RNN to model positional importance of sentences in the document. This architecture therefore models key sentences as well as keywords within those sentences jointly
- Get To The Point: Summarization with Pointer-Generator Networks paper tackles two important challenges:
- Accurately reproduce the salient information of source document.
- Efficiently handle OOV words.
This model combines the abstraction with the extraction. The pointer-generator architecture can copy words from source texts via a pointer and generate novel words from a vocabulary via a generator. With the pointing/copying mechanism, factual information can be reproduced accurately and OOV words can also be taken care in the summaries.
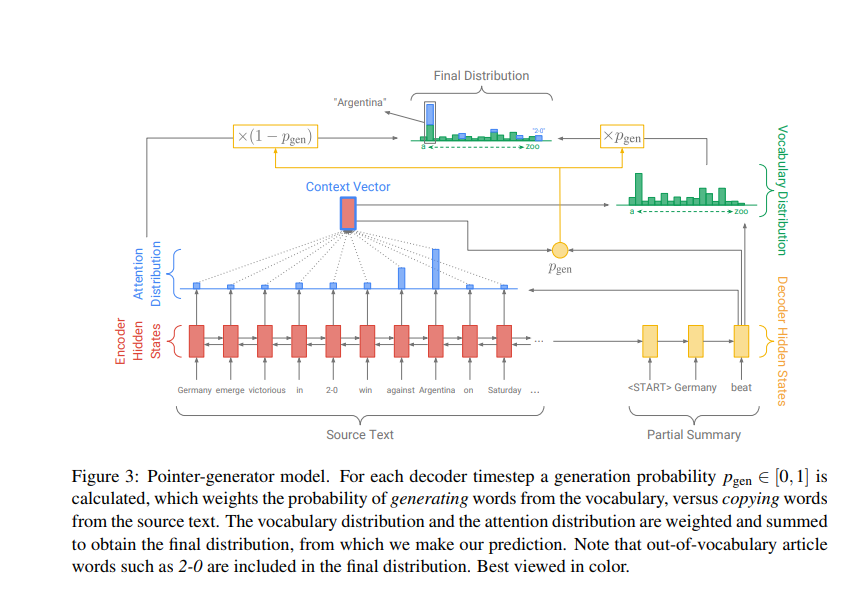

coverage mechanism and coverage loss
It avoids the attention mechanism to avoid repeatedly attending to the same locations and thus avoid generating repetitive text. coverage loss is used to penalize repeatedly attending to the same location.
coverage mechanism solves the word and sentence level repetitions and generating unnatural summaries.
- A Deep Reinforced model for abstractive summarization paper employs intra-temporal attention function to attend specific parts of the encoded input sequence, in addition to the decoder’s own hidden state and the previously generated words. This kind of attention prevents the model from attending over the same parts of the input on different decoding steps.
Attentional, RNN-based encoder-decoder models for abstractive summarization have achieved good performance on short input and output sequences. For longer documents and summaries however these models often include repetitive and incoherent phrases. We introduce a neural network model with a novel intra-attention that attends over the input and continuously generated output separately, and a new training method that combines standard supervised word prediction and reinforcement learning (RL). Models trained only with supervised learning often exhibit “exposure bias” – they assume ground truth is provided at each step during training. However, when standard word prediction is combined with the global sequence prediction training of RL the resulting summaries become more readable. We evaluate this model on the CNN/Daily Mail and New York Times datasets. Our model obtains a 41.16 ROUGE-1 score on the CNN/Daily Mail dataset, an improvement over previous state-of-the-art models. Human evaluation also shows that our model produces higher quality summaries.
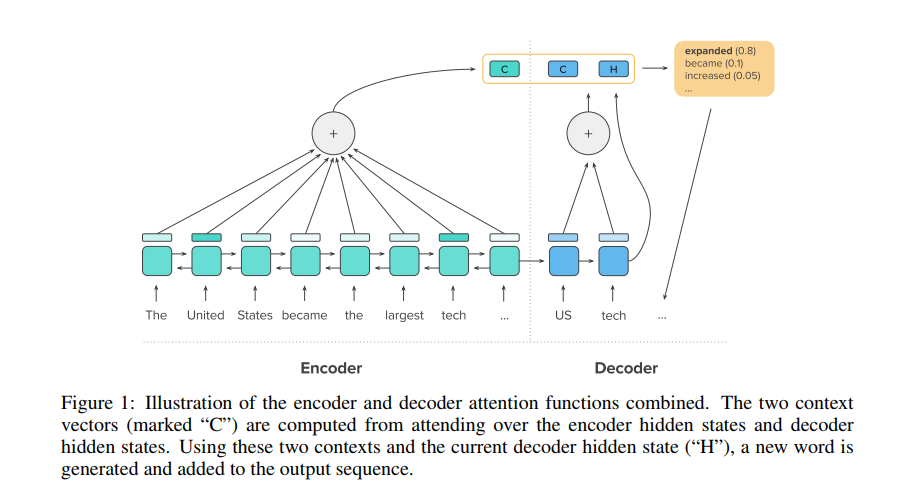
This paper follows an heuristic approach to avoid repetition that depends on the dataset used.
Another way to avoid repetitions comes from our observation that in both the CNN/Daily Mail and NYT datasets, ground-truth summaries almost never contain the same trigram twice. Based on this observation, we force our decoder to never output the same trigram more than once during testing. We do this by setting p(y_t) = 0 during beam search, when outputting y_t would create a trigram that already exists in the previously decoded sequence of the current beam.
- Controllable Abstractive Summarization paper describes mechanisms that enable the reader to control important aspects of the generated summary. It provides length constrained summarization, entity centric summarization, source specific summarization and remainder summarization.
Current models for document summarization disregard user preferences such as the desired length, style, the entities that the user might be interested in, or how much of the document the user has already read. We present a neural summarization model with a simple but effective mechanism to enable users to specify these high level attributes in order to control the shape of the final summaries to better suit their needs. With user input, our system can produce high quality summaries that follow user preferences. Without user input, we set the control variables automatically – on the full text CNN-Dailymail dataset, we outperform state of the art abstractive systems (both in terms of F1-ROUGE1 40.38 vs. 39.53 F1-ROUGE and human evaluation).
Below are the constrained summarization presented in this paper.
- Length-Constrained Summarization
Controlling summary length enables reading with different time spans. Length range bins are created with equal number of training documents. Then, special words are included in the vocabulary to fill out the missing spots to obtain the constrained length. At training, we prepend the ground truth markers. At test time, the length is controlled by prepending length marker token.
To enable the user to control length, we first quantize summary length into discrete bins, each representing a size range. Length bins are chosen so that they each contain roughly an equal number of training documents. We then expand the input vocabulary with special word types to indicate the length bin of the desired summary, which allows generation to be conditioned upon this discrete length variable. For training, we prepend the input of our summarizer with a marker that indicates the length of the ground-truth summary. At test time, we control the length of generated text by prepending a particular length marker token.
-
Entity-Centric Summarization
Preprending entity token instructs the model to focus on the sentences that mention these entity tokens during training. At testing, the generated summarized sentences will focus on the constrained entity sentences from the source document.
To enable entity-centric summaries, we first anonymize entities by replacing all occurrences of a given entity in a document by the same token. For a (document, summary) pair, each entity is replaced with a token from the set (@entity0, . . . , @entityN). This abstracts away the surface form, allowing our approach to scale to many entities and generalize to unseen ones. We then express that an entity should be present in the generated summary by prepending the entity token to the input — prepending @entity3 expresses that the model should generate a summary where @entity3 is present. In effect, this instructs the model to focus on sentences that mention the marked entities.
Higher accuracy is achieved:
1. when the constrained entities were from first few sentences of a document.
2. markers taken from the reference summary.
3. providing more entities improves summarization quality.
-
Source-Specific Summarization
Subjecting the summary to different style. Newspaper article sounds different from magazines, since they follow an unique style for different audiences. This constrain enable users to specify a preferred source style for a summary. Markers are preprended used to specify the style.
we introduce special marker tokens (@genSource0, . . . , @genSourceN) to express source desiderata. For training, we preprend the input with the marker corresponding to the ground-truth source. At inference, we control the style of generated summary by prepending different markers.
-
Remainder Summarization
If the reader, who has read the first paragraph needs a summary of only second paragraph, then remainder summarization is the constrain imposed. This requires more specific training data with position markers separating already read portion from the remainder part along with the corresponding summaries.
The original data is being adapted for remainder summarization based on the position information.
To enable remainder summarization without such data, we align summaries to full documents. Our procedure matches each reference summary sentence to its best matching document sentence based on ROUGE-L. For any position in the document, we remove sentences aligned before this point from the full summary and consider this shorter summary as the summary of the remainder.
In this blog, I have covered some of the major text summarization architectures. In the part2 blog, I will list out the challenges and solution strategies employed in providing a qualitative text summary.
Resources:
- Neural Abstractive Text Summarization with Sequence-to-Sequence Models: A Survey
- Controllable Abstractive Summarization - GITHUB
- Get To The Point: Summarization with Pointer-Generator Networks - GITHUB