Karthik Tech Blogs
Named Entity Recognition
Named Entity Recognition is the process of extracting entities present in sentences. This is an important aspect in information extraction from text documents. NER can also be used in conversational chats to extract entities such as location, time and many more. NER can also be trained to extract person names in information extraction of legal documents, survey forms etc. Hidden Markov Models (HMM), Support Vector Machines (SVM), Conditional Random Fields (CRF), and decision trees were common machine learning systems for NER. We will also explore about the Neural Network Architectures for NER.
In this blog, I will list out the NER Architectures from the paper titled A Survey on Recent Advances in Named Entity Recognition from Deep Learning models .
This survey paper primarily focuses on feature engineered machine learning models(supervised, semi-supervised and unsupervised systems), and on single language (English, German, etc) or a single domain (Biomedical, Finance etc).
Contents:
- Knowledge Based Systems
- Unsupervised Systems
- Feature-engineered supervised systems
- Feature inferring supervised systems
- Word level Architecture
- Character level Architecture
- Character + word level Architecture
Knowledge Based Systems
- Knowledge-based NER systems do not require annotated training data as they rely on lexicon (catalogue of a language’s words) resources and domain specific knowledge.
- When the lexicon is exhaustive, it contains all the entities, but creating an exhaustive lexicon is both time consuming process and requires domain experts for constructing and maintaining the knowledge resources.
- Precision is generally high for knowledge-based NER systems because of the lexicons, but recall is often low due to domain and language-specific rules and incomplete dictionaries.
Unsupervised Systems
A stepwise solution to tackle the challenges of entity boundary detection and entity type classification without relying on any handcrafted rules, heuristics, or annotated data. A noun phrase chunker followed by a filter based on inverse document frequency(IDF) extracts candidate entities from free text.
Classification of candidate entities into categories of interest is carried out by leveraging principles from distributional semantics.
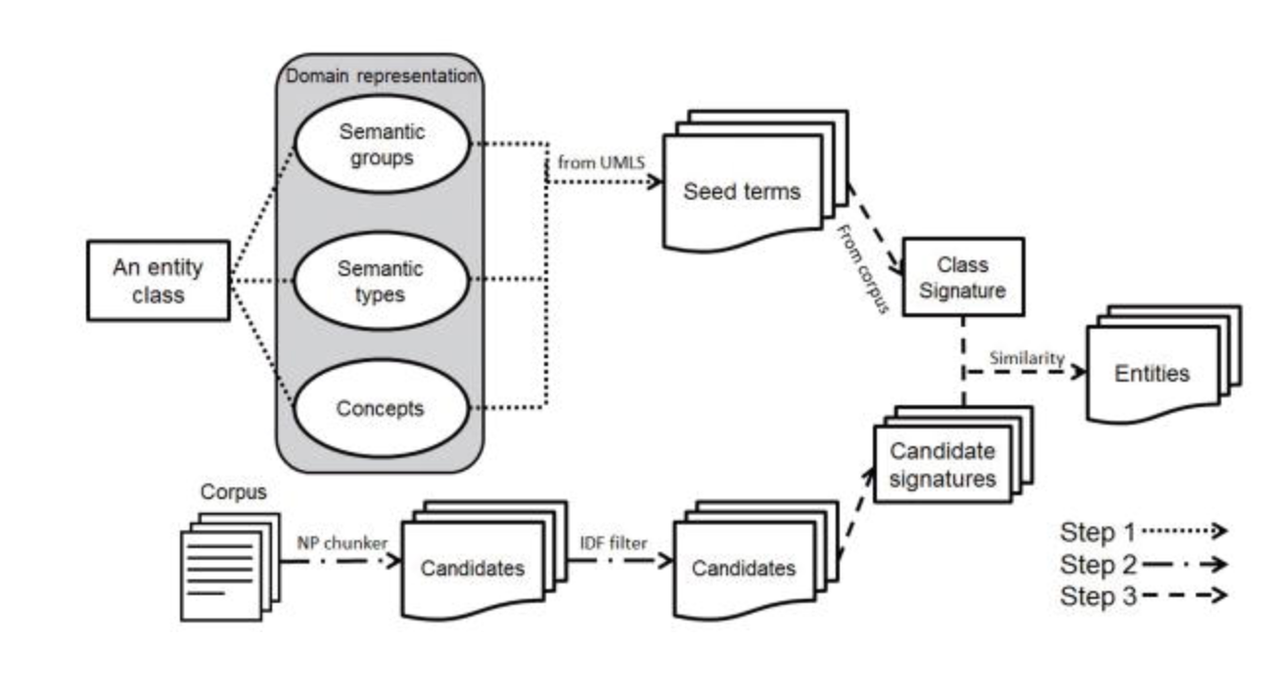
The model uses seeds to discover text having potential named entities, detects noun phrases and filters any with low IDF values, and feeds the filtered list to a classifier to predict named entity tags.
Feature-Engineered Supervised Systems
Supervised machine learning models learn to make prediction by training on example inputs and their expected outputs, and can replace human curated rules.
- Named Entity Recognition using an HMM-based Chunk Tagger This paper uses a Hidden Markov Model to recognize names, times and numerical quantities. The model uses multiple features to represent the entities.
Each word-feature consists of several sub-features, which can be classified into internal sub-features and external sub-features. The internal sub-features are found within the word and/or word string itself to capture internal evidence while external sub-features are derived within the context to capture external evidence.
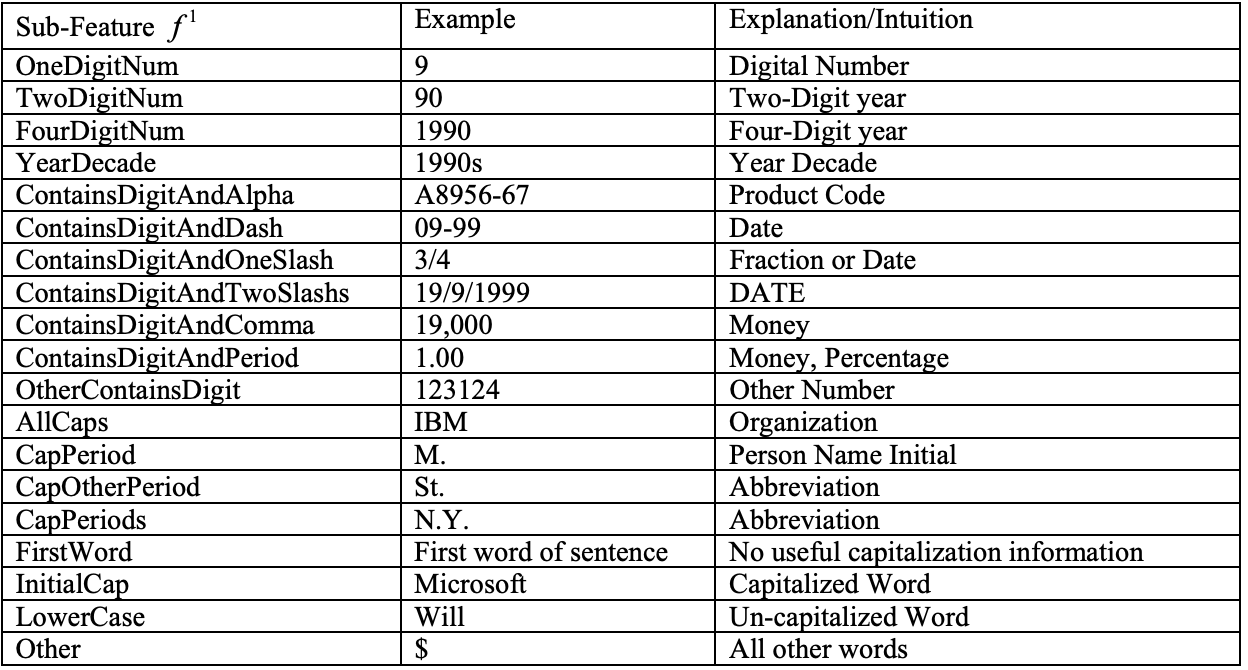
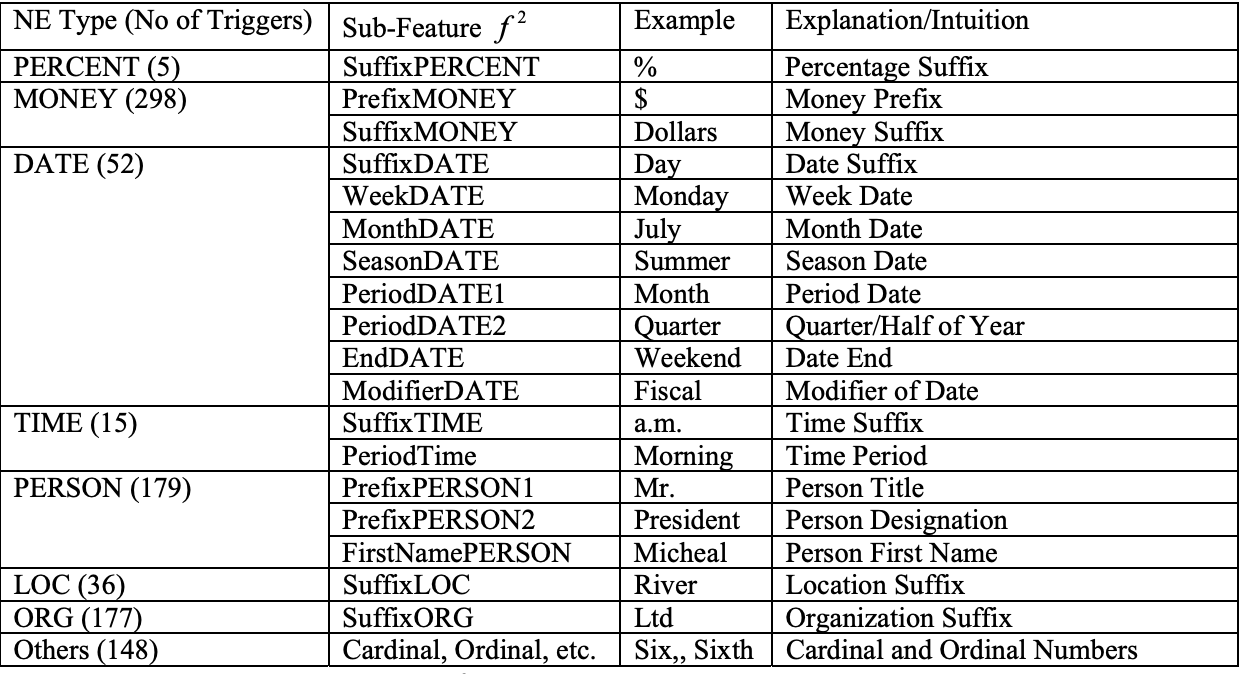
The Evaluation performance of HMM is better than rule based approaches because it captures the locality of entity representation that indicates names in text.
This paper divides NER into two sub problems such as Named Entity Recognition and Named Entity Classification. Named Entity recognition is performed as a greedy sequence tagging procedure. This tagging process makes use of three binary classifiers trained to recognize the B (Beginning), I (Inside), and O (Outside) labels. Named Entity classification is viewed as a 4–class classification problem (with LOC, PER, ORG, and MISC class labels), which employs multi-class learning algorithm.
The Feature representations are:
- Lexical: Word forms and their position in the window.
- Syntactic: Part-of-Speech tags and Chunk tags.
- Orthographic: Word properties with regard to how is it capitalized, (initial-caps, all-caps), the kind of characters that form the word (contains-digits, all-digits, alphanumeric, roman-number), the presence of punctuation marks (contains-dots, contains hyphen, acronym), single character patterns (lonely- initial, punctuation-mark, single-char), or the membership of the word to a predefined class (functional word1 ), or pattern (URL).
- Affixes: The prefixes and suffixes of the word.
- Word Type Patterns: Type pattern of consecutive words in the context.
- Left Predictions: The {B,I,O} tags being predicted in the current classification (at recognition stage), or the predicted category for entities in left context (at classification stage).
- Bag-of-Words: Form of the words in the window, without considering positions.
- Trigger Words: Triggering properties of window words. An external list is used to determine whether a word may trigger a certain Named Entity (NE) class. (e.g., “president” may trigger class PER).
- Gazetteer Features: Gazetteer information for window words.(e.g., for the entity “Bank of England”, both LOC and ORG labels would be activated if “England” is found in the gazetteer as LOC and “Bank of England” as ORG, respectively.
Feature-inferring neural network systems
One of the first neural network architectures for NER, with feature vectors constructed from orthographic features (e.g., capitalization of the first character), dictionaries and lexicons. Then this feature construction was replaced using word embeddings, which represented words in n-dimensional vector space. Learned a large collection of text corpus in an Unsupervised learning manner using skip-gram model.
The performance of NER system highly depend upon the pre-trained word embeddings.
Modern neural architectures for NER can be broadly classified into categories depending upon their representation of the words in a sentence.
Word level architectures
Each encoded word of a sentence is fed to a Recurrent Neural Network and each word is encoded by word embedding vector. That’s the reason, why the pre-trained word embeddings play an important role in the performance.
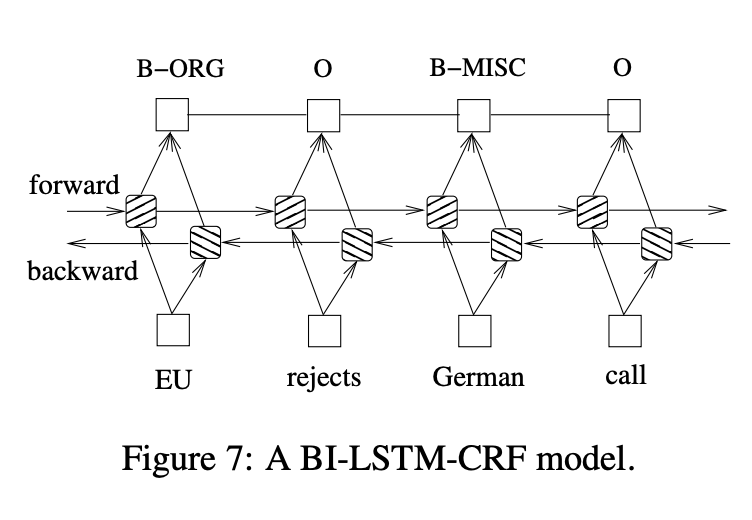
In this paper, we propose a variety of Long Short-Term Memory (LSTM) based models for sequence tagging. These models include LSTM networks, bidirectional LSTM (BI-LSTM) networks, LSTM with a Conditional Random Field (CRF) layer (LSTM-CRF) and bidirectional LSTM with a CRF layer (BI-LSTM-CRF). Our work is the first to apply a bidirectional LSTM CRF (denoted as BI-LSTM-CRF) model to NLP benchmark sequence tagging data sets. We show that the BILSTM-CRF model can efficiently use both past and future input features thanks to a bidirectional LSTM component. It can also use sentence level tag information thanks to a CRF layer. The BI-LSTMCRF model can produce state of the art (or close to) accuracy on POS, chunking and NER data sets. In addition, it is robust and has less dependence on word embedding as compared to previous observations.
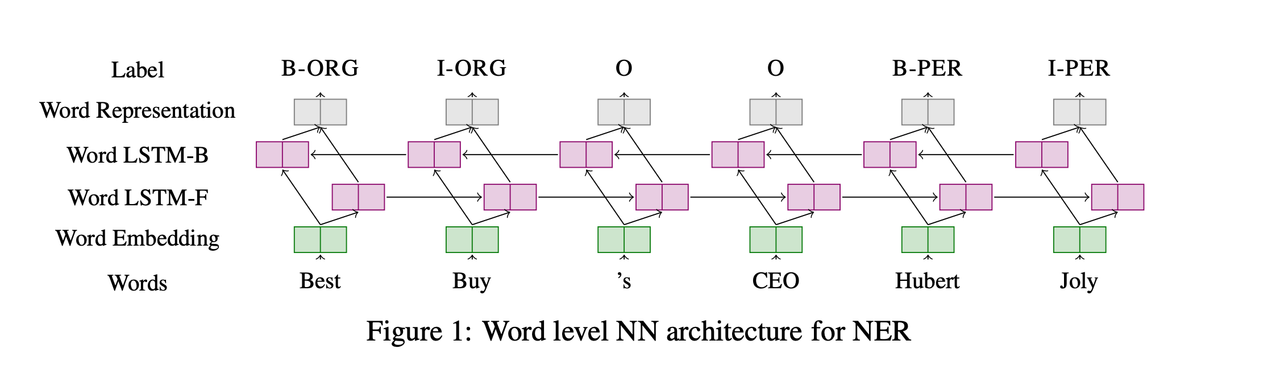
An input layer represents features at time t. The word feature uses one-hot-encoding. An input layer has the same dimensionality as feature size. An output layer represents a probability distribution over labels at time t. It has the same dimensionality as size of labels. Compared to feedforward network, a RNN introduces the connection between the previous hidden state and current hidden state. This recurrent layer is designed to store history information.
Long ShortTerm Memory networks are the same as RNNs, except that the hidden layer updates are replaced by purpose-built memory cells. As a result, they may be better at finding and exploiting long range dependencies in the data. LSTM solves the vanishing gradient problem that occurs with RNN.
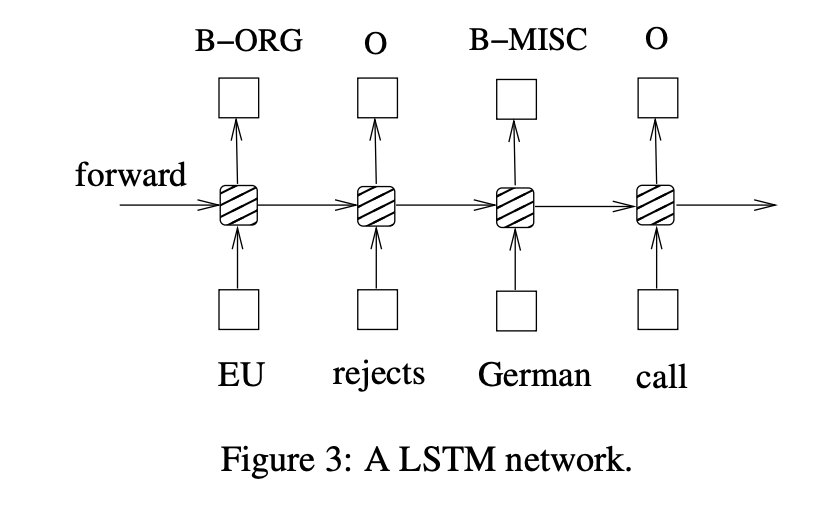
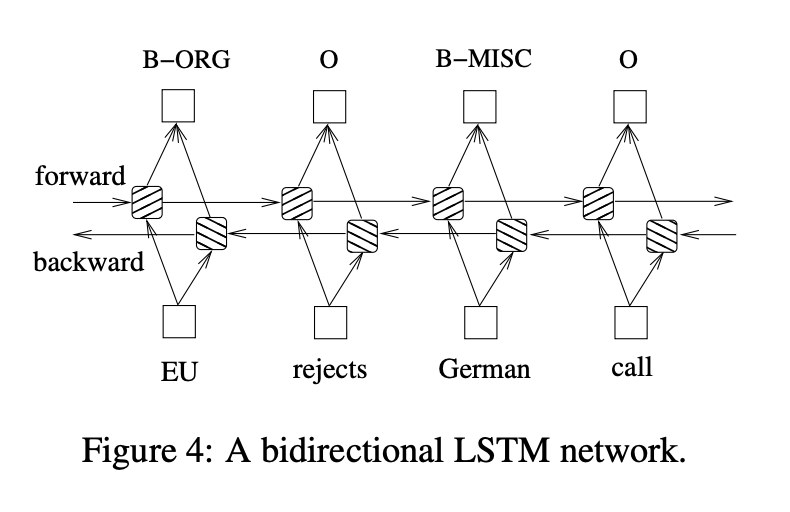
In sequence tagging task, we have access to both past and future input features for a given time, we can thus utilize a bidirectional LSTM network. In doing so, we can efficiently make use of past features (via forward states) and future features (via backward states) for a specific time frame. We train bidirectional LSTM networks using backpropagation through time (BPTT). The forward and backward passes over the unfolded network over time are carried out in a similar way to regular network forward and backward passes, except that we need to unfold the hidden states for all time steps.
Here the forward and backward for whole sentences is performed and only need to reset the hidden states to 0 at the beginning of each sentence. We have batch implementation which enables multiple sentences to be processed at the same time.
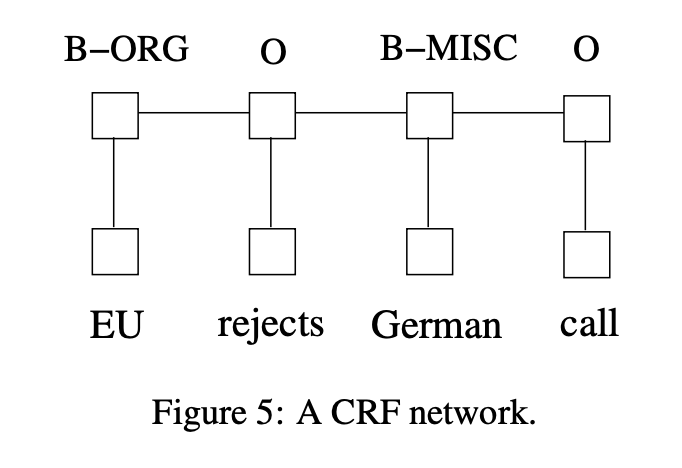
There are two different ways to make use of neighbour tag information in predicting current tags.
-
The first is to predict a distribution of tags for each time step and then use beam-like decoding to find optimal tag sequences. The work of maximum entropy classifier and Maximum entropy Markov models (MEMMs) fall in this category.
-
The second one is to focus on sentence level instead of individual positions, thus leading to Conditional Random Fields (CRF) models.
It has been shown that CRFs can produce higher tagging accuracy in general. It is interesting that the relation between these two ways of using tag information bears resemblance to two ways of using input features, and the results in this paper confirms the superiority of BI-LSTM compared to LSTM.
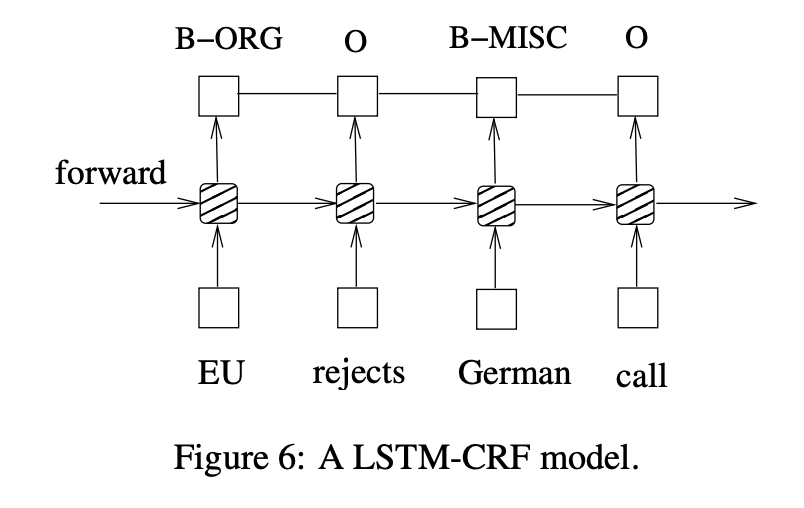
This network can efficiently use past input features via a LSTM layer and sentence level tag information via a CRF layer.
A CRF layer has a state transition matrix as parameters. With such a layer, we can efficiently use past and future tags to predict the current tag, which is similar to the use of past and future input features via a bidirectional LSTM network.
Similar to a LSTM-CRF network, we combine a bidirectional LSTM network and a CRF network to form a BI-LSTM-CRF network.
Character level architecture
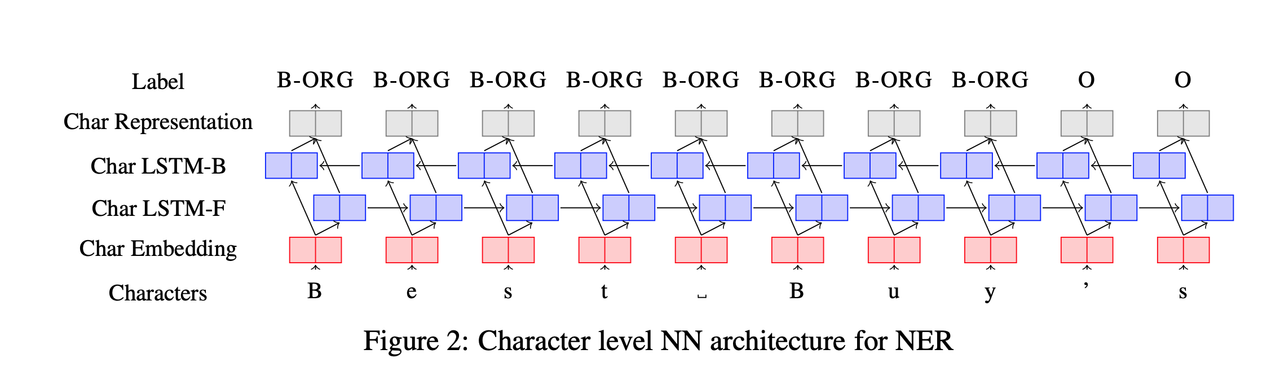
In this model, a sentence is taken to be a sequence of characters. This sequence is passed through an RNN, predicting labels for each character. Character labels transformed into word labels via post processing.
The potential of character NER neural models was first highlighted using highway networks over convolution neural networks (CNN) on character sequences of words and then using another layer of LSTM + softmax for the final predictions.
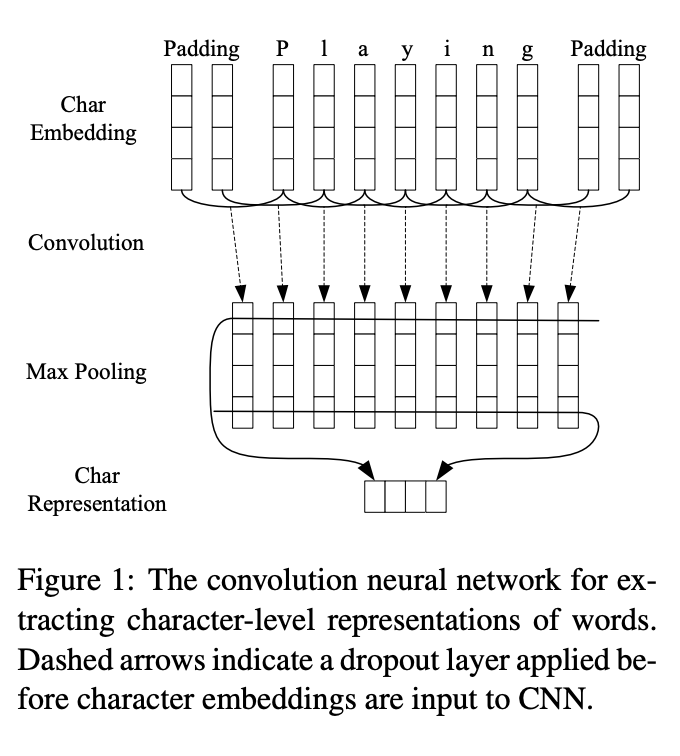
- Character-Aware Neural Language Models
We describe a simple neural language model that relies only on character-level inputs. Predictions are still made at the word-level. Our model employs a convolutional neural network (CNN) and a highway network over characters, whose output is given to a long short-term memory (LSTM) recurrent neural network language model (RNN-LM).
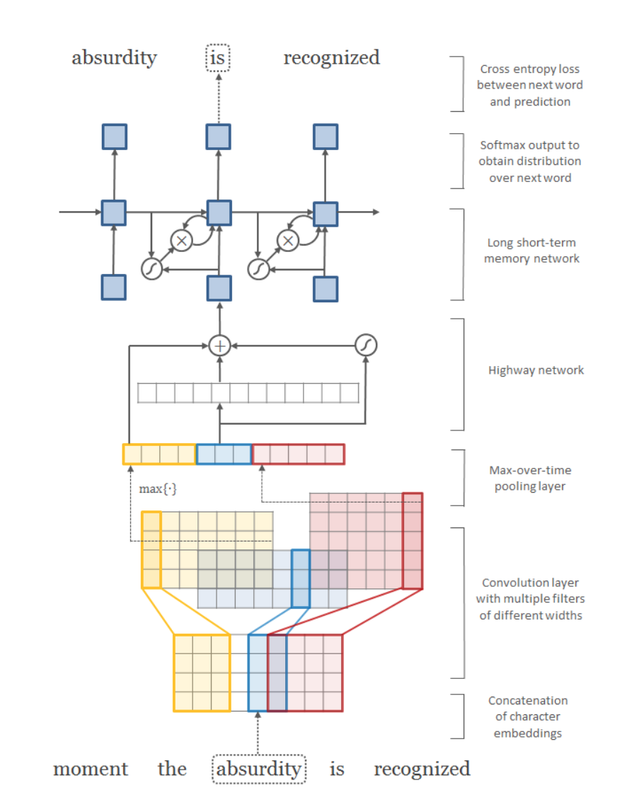
Architecture of our language model applied to an example sentence. Best viewed in color. Here the model takes absurdity as the current input and combines it with the history to predict the next word. First layer performs a lookup of character embeddings (of dimension four) and stacks them to form the matrix Ck . Then convolution operations are applied between Ck and multiple filter matrices. Note that in the above example we have twelve filters—three filters of width two (blue), four filters of width three (yellow), and five filters of width four (red). A max-over-time pooling operation is applied to obtain a fixed-dimensional representation of the word, which is given to the highway network. The highway network’s output is used as the input to a multi-layer LSTM. Finally, an affine transformation followed by a softmax is applied over the hidden representation of the LSTM to obtain the distribution over the next word. Cross entropy loss between the (predicted) distribution over next word and the actual next word is minimized. Element-wise addition, multiplication, and sigmoid operators are depicted in circles, and affine transformations (plus nonlinearities where appropriate) are represented by solid arrows.
This Language Model Architecture was used for Vietnamese NER and various other languages like Chinese and achieved state of the art performance.
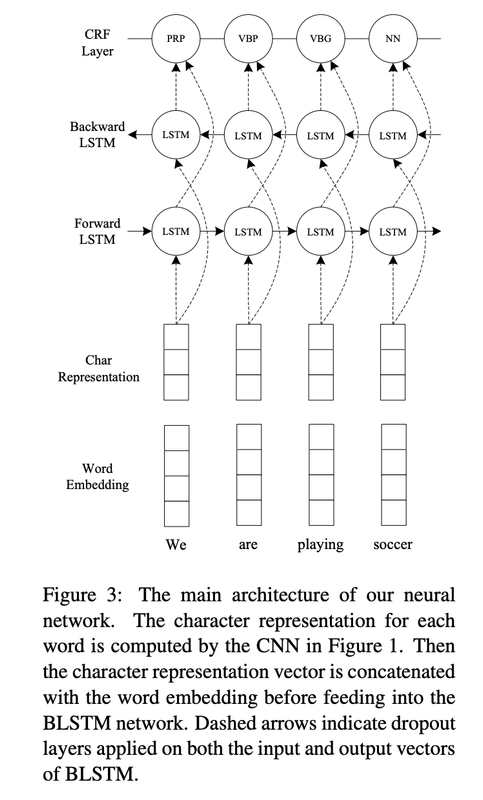
We describe and evaluate a character-level tagger for language-independent Named Entity Recognition (NER). Instead of words, a sentence is represented as a sequence of characters. The model consists of stacked bidirectional LSTMs which inputs characters and outputs tag probabilities for each character. These probabilities are then converted to consistent word level named entity tags using a Viterbi decoder.

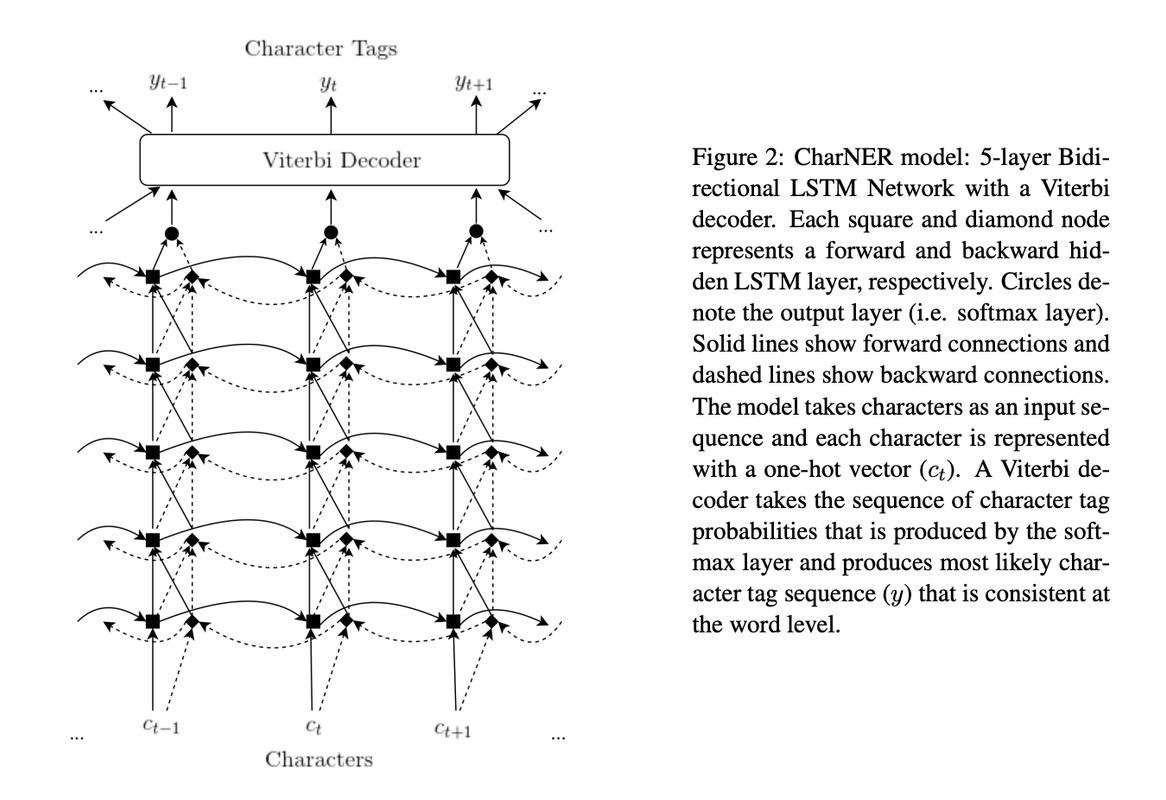
The deep BLSTM gives us a tag distribution for each character position.
The problem this paper solves is
In early experiments, we observed that the most probable character tags within a word were not always consistent. For example, the model may assign higher probability to person (P) tags in the beginning of a word and organization (G) tags at the end of the same word. Even though the deep BLSTM has access to both left and right input contexts, it is unable to learn word level consistency for output tags.
Given a character sequence c1, c2, …, cn, and a tag set y ∈ Y, the decoder takes output tag probabilities from the LSTM, as emission probabilities and exploits transition matrices that only allow tags consistent within a word.
Three types of transitions can occur between consecutive character tags according to the position of the character at hand.
- A character is either followed by a fellow character in the same word (c → c)
- It can be the last character of a word followed by space (c → s) where c denotes a character inside word boundaries and s denotes the delimiter space.
- It can be a space character followed by the first character of the next word (s → c).

We describe an LSTM-based model which we call Byte-to-Span (BTS) that reads text as bytes and outputs span annotations of the form [start, length, label] where start positions, lengths, and labels are separate entries in our vocabulary. Because we operate directly on unicode bytes rather than language specific words or characters, we can analyze text in many languages with a single model. Due to the small vocabulary size, these multilingual models are very compact, but produce results similar to or better than the state-of-the-art in Part-of-Speech tagging and Named Entity Recognition that use only the provided training datasets (no external data sources). Our models are learning “from scratch” in that they do not rely on any elements of the standard pipeline in Natural Language Processing (including tokenization), and thus can run in standalone fashion on raw text.
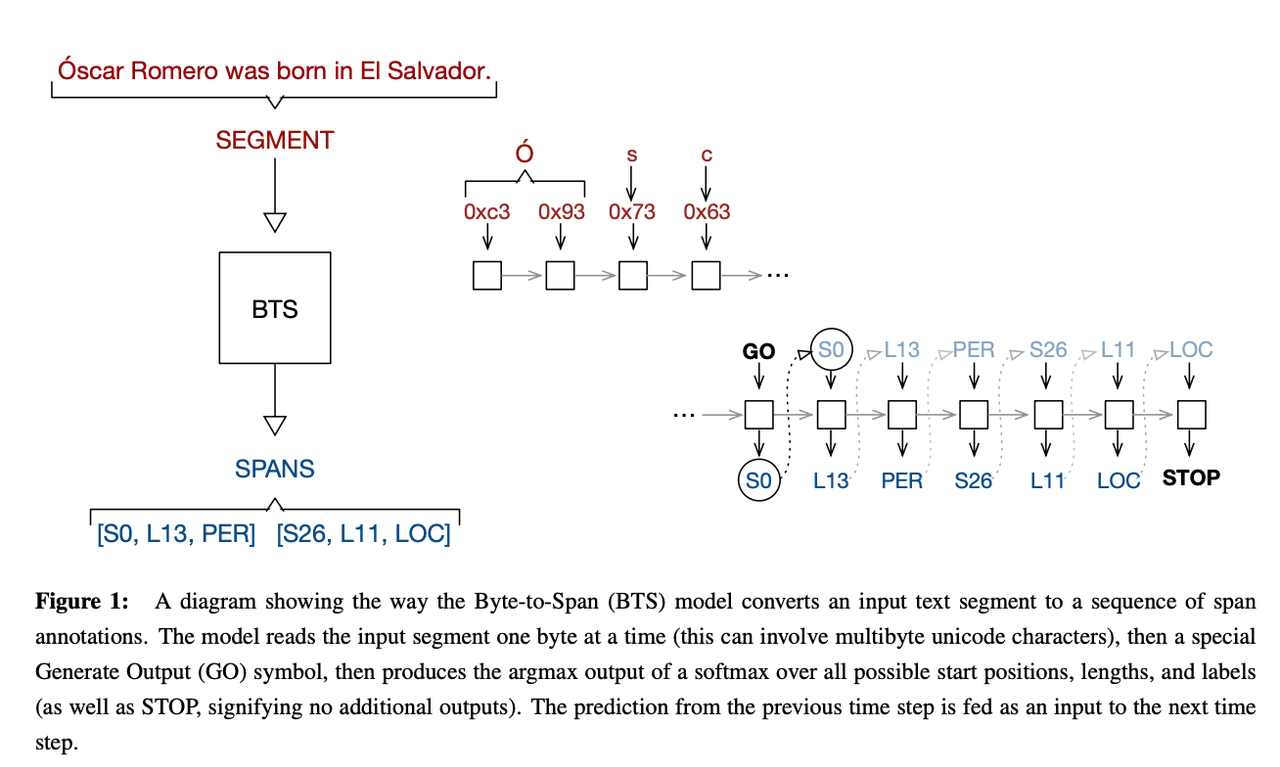
Sequence of unicode bytes is read, rather than producing a label for each word, and they are producing triples [start, length, label], that correspond to the spans of interest, as a sequence of three separate predictions. This forces the model to learn how the components of words and labels interact so all the structure typically imposed by the NLP pipeline are left to the LSTM to model.
Character + word level architectures
Systems combining word context and the characters of a word have proved to be strong NER systems that need little domain specific knowledge or resources.
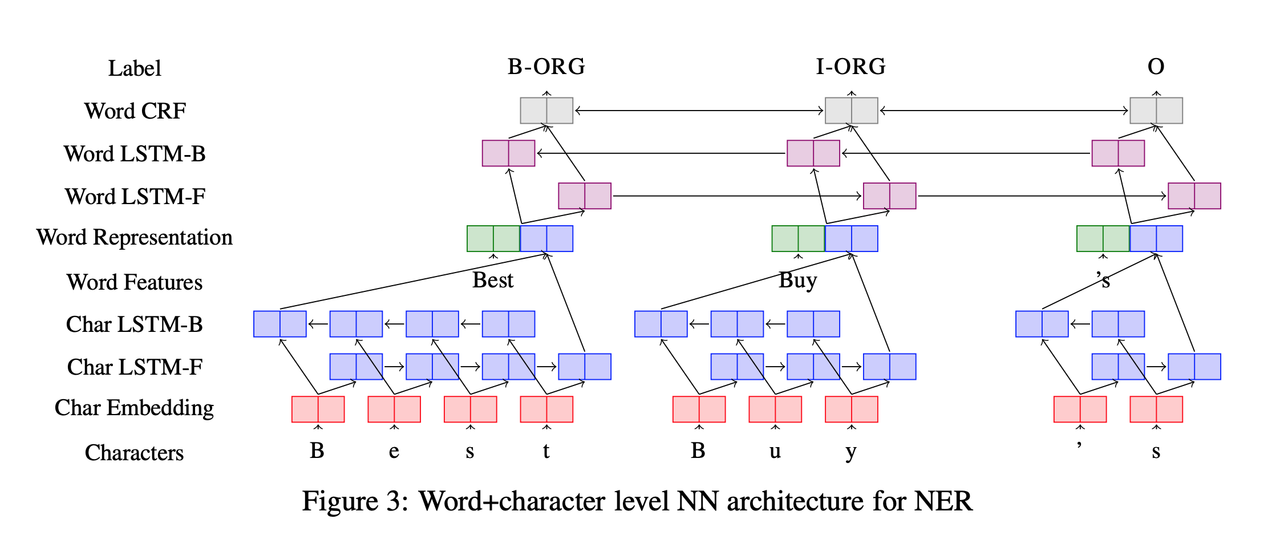
There are two base models in this category.
The first type of model represents words as a combination of a word embedding and a convolution over the characters of the word, follows this with a Bi-LSTM layer over the word representations of a sentence, and finally uses a softmax or CRF layer over the Bi-LSTM to generate labels.
In this paper, we introduce a novel neutral network architecture that benefits from both word- and character-level representations automatically, by using combination of bidirectional LSTM, CNN and CRF. Our system is truly end-to-end, requiring no feature engineering or data preprocessing, thus making it applicable to a wide range of sequence labeling tasks.
We first use convolutional neural networks (CNNs) to encode character-level information of a word into its character-level representation. Then we combine character- and word-level representations and feed them into bi-directional LSTM (BLSTM) to model context information of each word. On top of BLSTM, we use a sequential CRF to jointly decode labels for the whole sentence.
The second type of model concatenates word embeddings with LSTMs (sometimes bi-directional) over the characters of a word, passing this representation through another sentence-level Bi-LSTM, and predicting the final tags using a final softmax or CRF layer.
In this paper, we introduce two new neural architectures—one based on bidirectional LSTMs and conditional random fields, and the other that constructs and labels segments using a transition-based approach inspired by shift-reduce parsers. Our models rely on two sources of information about words: character-based word representations learned from the supervised corpus and unsupervised word representations learned from unannotated corpora.
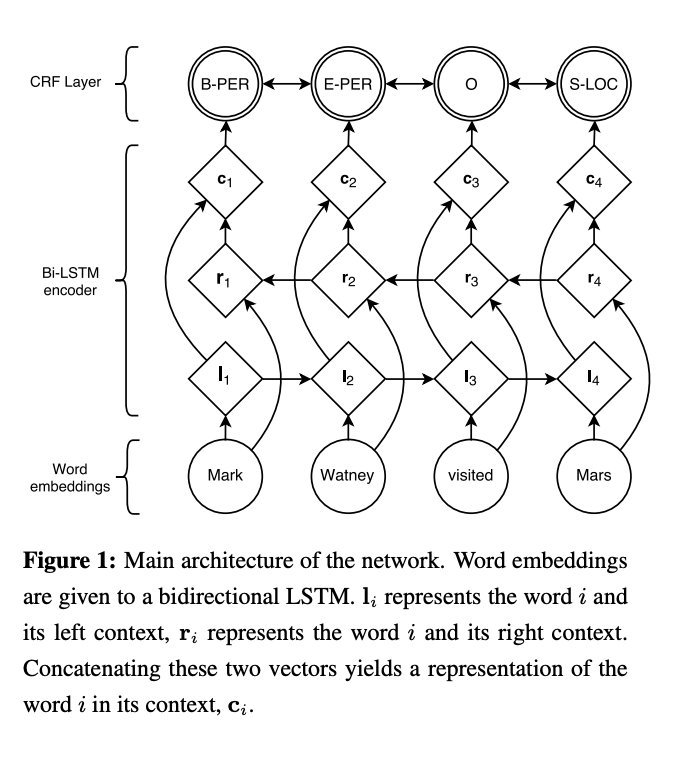
This model was implemented in NeuroNER toolkit with the main goal of providing easy usability and allowing easy plotting of real time performance and learning statistics of the model.
In this paper, we introduce an attentional neural model which only uses language universal phonological character representations with word embeddings to achieve state of the art performance in a monolingual setting using supervision and which can quickly adapt to a new language with minimal or no data. We demonstrate that phonological character representations facilitate cross-lingual transfer, outperform orthographic representations and incorporating both attention and phonological features improves statistical efficiency of the model in 0-shot and low data transfer settings with no task specific feature engineering in the source or target language.
This paper models the words of a sentence at the type level and the token level. At the type level (ignorant of sentential context), we use bidirectional character LSTMs to compose characters of a word to obtain its word representation and concatenate this with a word embedding that captures distributional semantics. This can memorize entities or capture morphological and suffixal clues that can help at a discriminative task like NER. Type level word representations with bidirectional LSTMs was composed to obtain token level representations. Using token level word representations along with an attentional context vector for each word based on the sequence of characters it contains, we generate score functions used by a Conditional Random Field (CRF) for inference. To facilitate transfer across languages with different scripts, we use Epitran and PanPhon.
Character + Word + affix model
We propose a practical model for named entity recognition (NER) that combines word and character-level information with a specific learned representation of the prefixes and suffixes of the word.
This paper augments the character+word NN architecture with one of the most successful features from feature-engineering approaches: affixes.
This paper showed that affix embeddings capture complementary information to that captured by RNNs over the characters of a word, that selecting only high frequency (realistic) affixes was important, and that embedding affixes was better than simply expanding the other embeddings to reach a similar number of hyper-parameters.
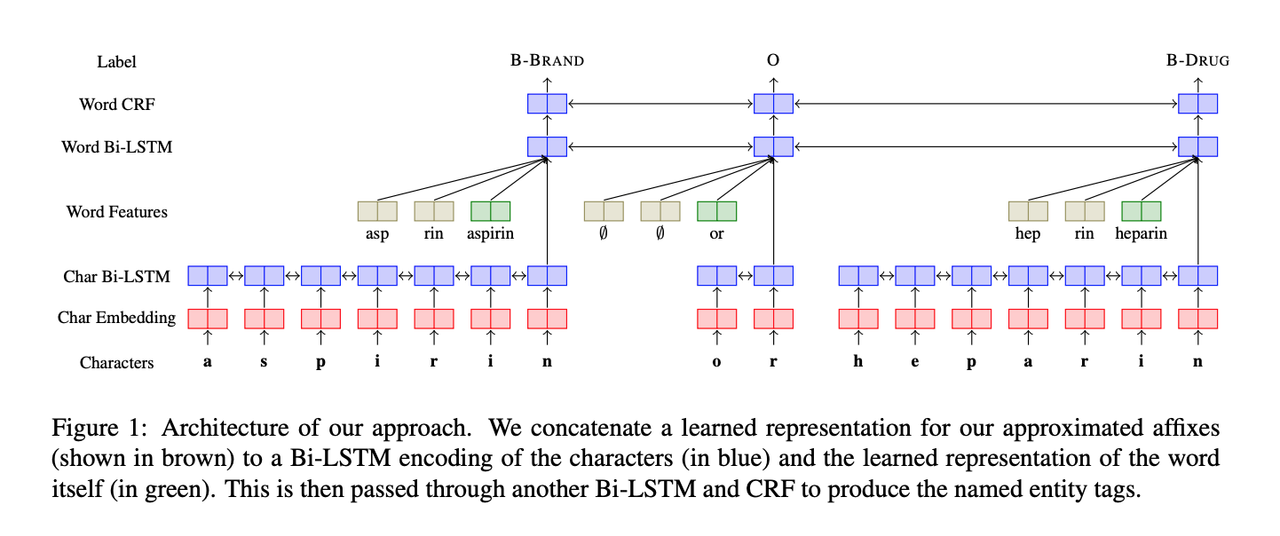
Some changes to the character+word model was made to learn affix embeddings alongside the word embeddings and character RNNs. They considered all n-gram prefixes and suffixes of words in the training corpus, and selected only those whose frequency was above a threshold, T.
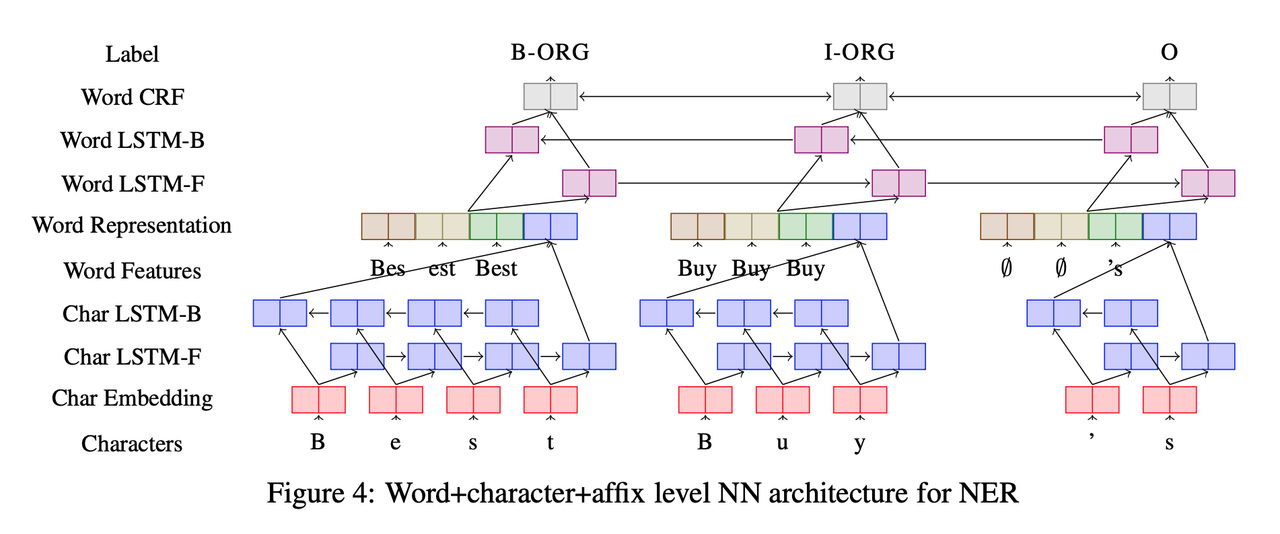
Conclusion
Our first finding from the survey is that feature-inferring NN systems outperform feature-engineered systems, despite the latter’s access to domain specific rules, knowledge, features, and lexicons.
Neural network models generally outperform feature-engineered models, character+word hybrid neural networks generally outperform other representational choices, and further improvements are available by applying past insights to current neural network models.
Written on April 12th, 2020 by Karthik